Lua速通教程
Lua速通教程
学习目标:
能够使用Lua脚本在Unity中进行游戏Game Play逻辑的开发
适用人群:
前两个阶段适合有一定编程语言基础的(至少会一门编程语言,如C#,Python)的人学习。
后两个阶段则时候有Unity使用基础的人学习。
0. 攻略大纲
- 第一阶段:Lua基础
- Lua介绍:简要了解Lua的历史、特点和在游戏开发中的应用。
- 环境配置:配置安装Lua环境,选择合适的ide。
- 基础语法:学习Lua的变量、数据类型、操作符和控制结构。
- 表:Lua中表(table)的具体使用。
- **代码组织(环境,模块,包)**:如何使用Lua的模块和包来组织代码。
- 第二阶段:Lua进阶
- 文件I/O:学习如何在Lua中进行文件读写。
- 错误处理:理解Lua中的错误处理和异常机制。
- 协同程序(coroutine):介绍Lua的协同程序,这是Lua的一大特色。
- 反射(Reflection):介绍Lua中的反射机制与具体的反射写法。
- 序列化与反序列化:介绍lua中如何将表序列化与反序列化。
- 垃圾收集(GC):介绍lua的垃圾回收机制和实际开发时需要注意的点。
在每个阶段之后,我们将进行简短的练习和问题解答。
1. Lua介绍
1.1 历史背景
Lua是在1993年由巴西里约热内卢天主教大学的Roberto Ierusalimschy, Luiz Henrique de Figueiredo, 和 Waldemar Celes开发的。
最初设计为一种简单的脚本语言,用于配置文件和数据解析。但随着时间的发展,Lua已经成为一种功能强大的轻量级编程语言。
1.2 应用领域
游戏开发:
许多游戏使用Lua来编写游戏逻辑和UI。
例如《魔兽世界》、《星际争霸II》和《Garry’s Mod》。
Lua在快速原型开发和游戏测试中非常好用,因为它允许开发者快速迭代和测试代码而无需频繁的编译过程。
嵌入式系统:
由于Lua的轻量级和可嵌入性,它常被用于嵌入式系统,如网络设备和家用电器。
Web应用:
Lua也被用于服务器端脚本,尤其是与Nginx结合时。
1.3 Lua的优缺点
优点:
- 易学易用:
Lua具有非常简洁和清晰的语法,上手快,非常适合初学者。 - 可移植性:
Lua拥有高度的可移植性,几乎可以在所有操作系统和平台上运行。 - 高效率:
Lua的执行速度非常快,特别是当与Just-In-Time(JIT)编译器结合使用时。 - 高灵活:
Lua的表(table)结构非常灵活,可以用作数组、字典,甚至可以模拟面向对象的特性。 - 丰富的社区支持:
Lua有一个活跃的开发社区,提供大量文档、教程和第三方库。 - 广泛的应用:
在游戏开发和嵌入式系统中有广泛的应用案例。
缺点:
- 性能局限:
虽然Lua的性能很好,但与编译语言(如C/C++)相比,它在处理大规模复杂计算任务时可能会显得慢一些。
对于大多数游戏开发场景,Lua的性能已经足够。通常,只有在非常计算密集的任务中,性能差异才会变得明显。 - 面向对象编程的限制:
Lua本身不是一种面向对象的语言,虽然可以通过表和元表来模拟对象,但这种方式对于习惯了传统面向对象语言的开发者来说可能不够直观。 - 标准库的限制:
与Python等语言相比,Lua的标准库较小,对于某些任务可能需要依赖外部库或自行实现功能。 - 类型系统:
Lua是一种动态类型语言,这可能导致在复杂应用中出现类型相关的错误,这些错误在编译时不容易被发现。
结论:
Lua是一个强大的工具,特别是在需要快速开发和嵌入脚本的场合。它的简单性、灵活性和高效性使其成为游戏开发和嵌入式系统的热门选择。然而,它也有其局限性,特别是在性能和面向对象编程方面。
选择使用Lua时,需要根据项目的具体需求和上下文来权衡这些因素。
2 环境配置
2.1 安装Lua环境
下载Lua解释器:
你可以从Lua的官方网站 lua.org 下载Lua解释器。网站上提供了源代码,你可以在大多数操作系统上编译安装。
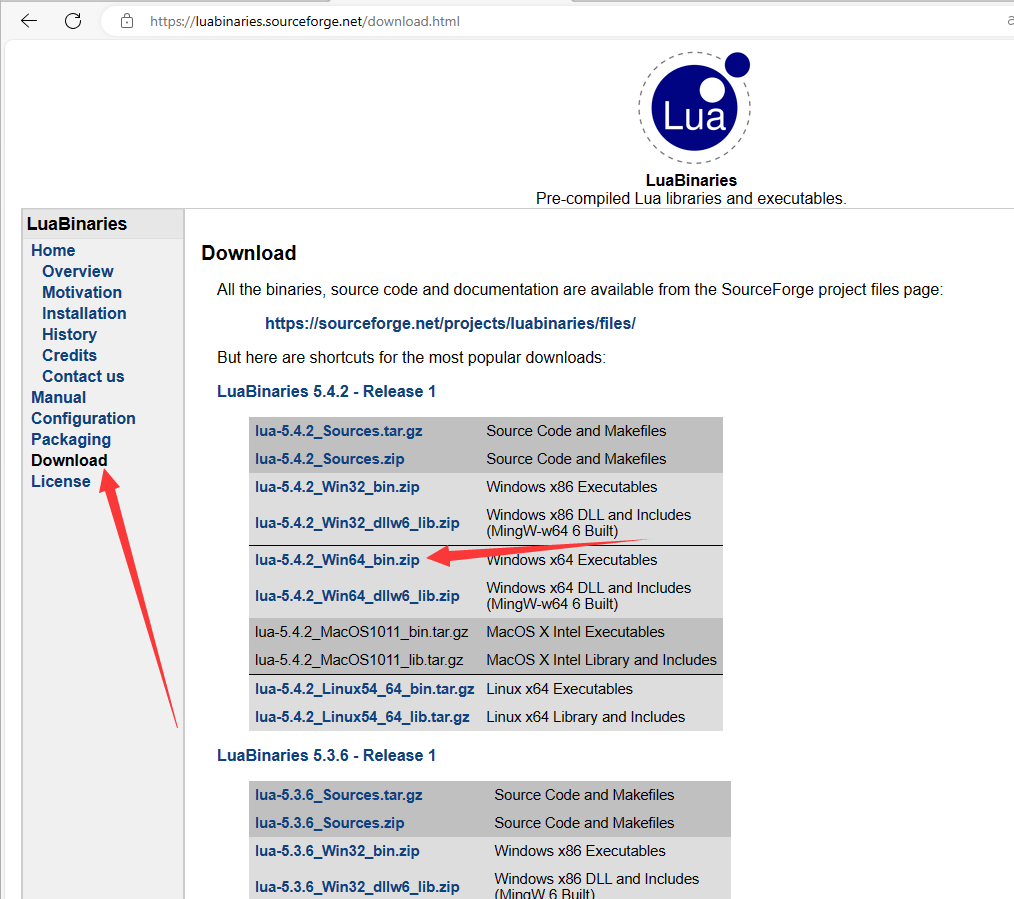
配置系统环境变量:
- 右键点击“此电脑”或“我的电脑”,选择“属性”。
- 点击“高级系统设置”。
- 在“系统属性”窗口中,点击“环境变量”。
- 在“系统变量”下,找到并选择“Path”,点击“编辑”。
- 点击“新建”,添加Lua解释器的安装路径。
- 点击“确定”保存更改。
检查Lua环境是否配置成功:

以下是三种比较主流的LuaIDE,根据自身情况和喜好,三选一即可。
个人推荐VSCode
VSCode配置
VS Code是一个轻量级、功能强大的编辑器,它通过插件支持Lua语言。
配置步骤如下:
安装VS Code:
如果你还没有安装VS Code,可以从其官方网站下载并安装。安装Lua插件:
- Lua
提供了Lua语言的基本支持和增强功能。 - LuaDebug
针对Lua语言的调试插件- 断点调试:允许你设置断点,逐步执行Lua代码。
- 变量检查:在调试期间查看和修改变量的值。
- 调试控制:提供了继续、暂停、停止、逐步进入等调试控制功能。
- Code Runner
一个通用的代码运行插件,支持多种编程语言,包括Lua。
- Lua
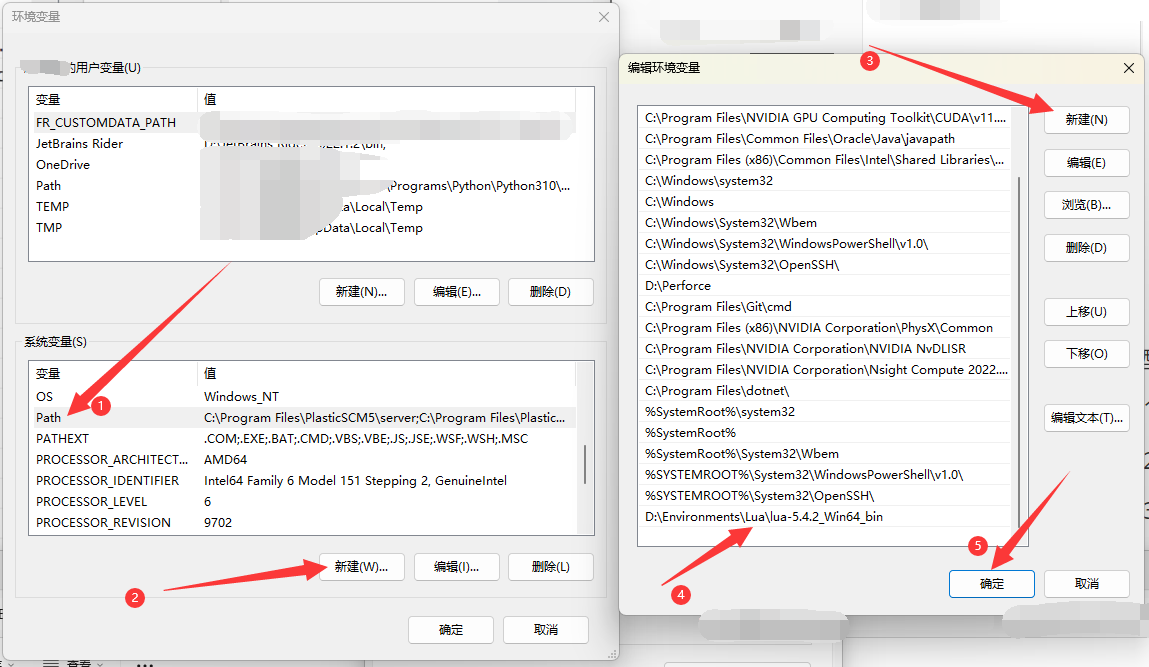
设置CodeRunner的Lua解释器路径
打开 executorMap 设置
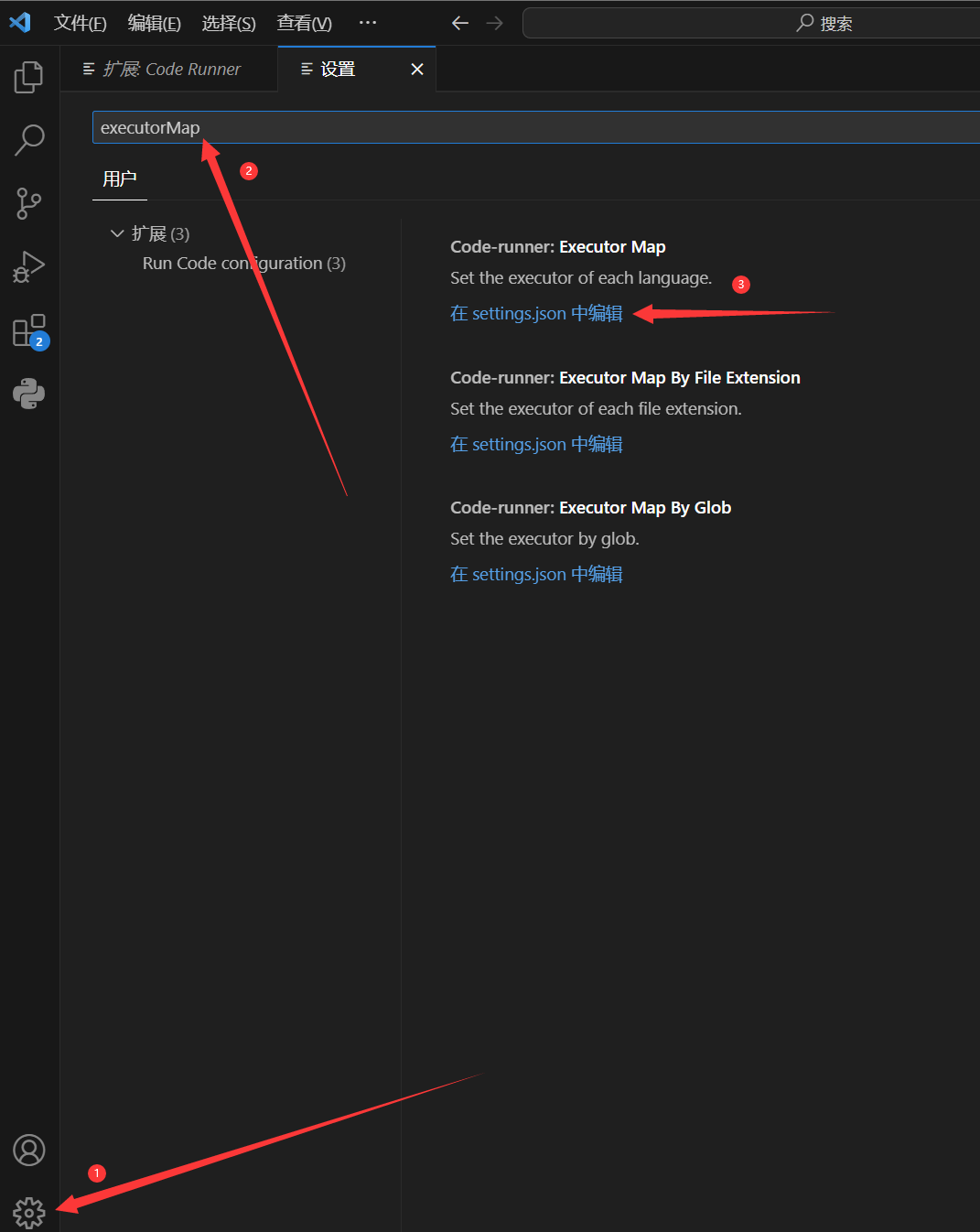增加lua解释器路径
1
2
3"code-runner.executorMap": {
"lua": "D:\\Environments\\Lua\\lua-5.4.2_Win64_bin\\lua54.exe"
}![[语言学习/Lua/assets/image-6.png]]
测试是否成功:
安装完插件后,就可以在VS Code中创建和编辑Lua文件了。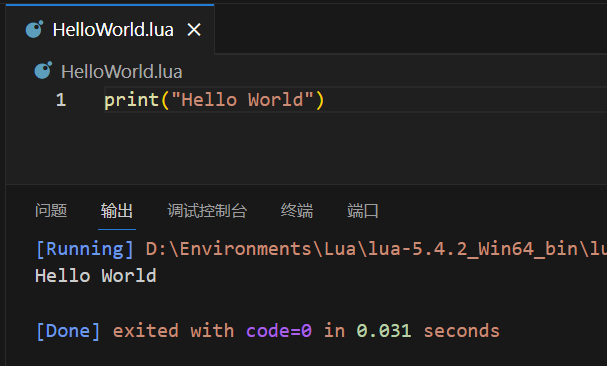
Ride配置
Rider是由JetBrains开发的一个强大的跨平台IDE,支持多种语言,但需要注意的是,Rider本身不原生支持Lua。要在Rider中使用Lua,你可能需要借助插件,如 EmmyLua。
- 安装Rider:
首先,确保你已经安装了Rider。 - 查找并安装Lua插件:
- 在Rider中,打开
File>Settings>Plugins。 - 搜索Lua相关的插件,如EmmyLua。
- 安装插件并重启Rider。
- 在Rider中,打开
- 开始编写Lua代码:
安装好插件后,你就可以在Rider中创建Lua文件并开始编程了。
在线Lua环境工具
对于快速实验或学习Lua,使用在线工具是一个方便的选择。
这里有一些推荐的在线Lua环境:
- Repl.it:
Repl.it 提供了一个简单的在线Lua编程环境,无需安装任何东西。 - Lua Demo:
Lua Demo 是Lua官方网站提供的一个简易在线运行环境。 - TutorialsPoint Lua Compiler:
TutorialsPoint 也提供在线Lua编译器。
使用这些在线工具,你可以直接在浏览器中编写和运行Lua代码,非常适合初学者或进行小型实验。
3 基础语法
3.1 数据类型
3.1.1 全部8种数据类型
| 数据类型 | 用途 | 值/引用 | 特点 | 示例 |
|---|---|---|---|---|
| Nil (空) |
表示不存在或无效的值 | 值类型 | 和其他语言的null相同 | a = nil 表示 a 是一个无值变量。 |
| Boolean (布尔) |
用于条件判断 | 值类型 | isLuaEasy = true |
|
| Number (数字) |
用于存储数字 | 值类型 | Lua中的数字类型默认为双精度浮点数(没有单独的整数或单浮点类型) | num1 = 10 |
| String (字符串) |
用于存储文本 | 值类型 | 字符串在Lua中是不可变的,连接两个字符串时实际上会创建一个新的字符串 | greeting = "Hello" |
| Table (表) |
数据结构类型,用于嵌套存储其他数据类型 | 引用类型 | Lua中唯一的数据结构类型,可以用作数组、字典或对象 | 数组示例:arr = { "apple", "banana", "cherry" } 字典示例: person = { name = "Alice", age = 30 } |
| Function (函数型) |
用于调用事件和方法 | 引用类型 | 在Lua中,函数也是一种数据类型,可以存储在变量中,作为参数传递,或作为其他函数的返回值 | add = function(a, b) return a + b end |
| Thread (线程型) |
用于实现协同程序(coroutines) | 引用类型 | 线程在Lua中可以用来执行非阻塞操作或并行执行 | 见表下 |
| Userdata (用户数据型) |
用于表示由应用程序或C语言代码创建的数据类型 | 引用类型 | 通常用于Lua绑定到C语言库 | 略 |
线程案例补充:
1 | |
3.1.2 值类型与引用类型
在Lua中,数据类型可以根据它们是如何被存储和传递(值传递或引用传递)来分类为“值类型”和“引用类型”。
了解Lua中哪些类型是值类型,哪些是引用类型,对于理解变量如何存储和传递、以及如何在函数间传递参数非常重要。这也对于理解性能考量和内存管理方面的影响至关重要。
值类型
Nil(空)
Boolean(布尔型)
Number(数字型)
String(字符串型)
这些类型的变量直接存储它们的值。
当这些类型的变量被赋值给另一个变量时,它们的值会被复制。
在Lua中,即使是字符串也被当作值类型,尽管在许多其他语言中,字符串可能被视为引用类型。
引用类型
- Table(表)
- Function(函数型)
- Thread(线程型)
- Userdata(用户数据型)
这些类型的变量存储的是对它们数据的引用。
这意味着,当你将这类变量赋值给另一个变量时,新变量实际上是指向原始数据的引用。
因此,修改引用类型的变量可能会影响原始数据。
重要说明:
- 当你操作一个引用类型的变量时,你实际上是在操作一个指向数据的引用,而不是数据本身。
- 值类型在操作过程中,值的副本会被创建和传递,而不会影响原始数据。
3.1.3 动态类型与类型转换
动态类型
Lua是动态类型语言,变量不用声明类型,在首次赋值时自动确定类型。
在Lua中,变量没有预先定义的类型,相反,类型是与值相关联的,而不是与变量。这意味着同一个变量在不同时间可以持有不同类型的值。
这样的动态类型给lua带来了:
- 灵活性:
你可以将任何类型的值赋给任何变量。
例如,一个原本存储数字的变量之后可以被赋予一个字符串。 - 简洁性:
在定义变量时不需要指定类型,Lua运行时会自动处理变量的类型。 - 动态:
变量类型可以在运行时改变,这给编程带来了极大的灵活性,但同时也要求程序员更加注意类型相关的错误。
类型检查
在Lua中,类型检查通常是通过使用内置的type函数来完成的。
Lua没有提供类似于C#中的is或as操作符,但你可以使用type函数来获取一个值的类型,然后根据需要进行比较或相应的处理。
以下是针对Lua支持的所有基本数据类型的type函数的使用示例:
Nil(空)
1
2
3if type(var) == "nil" then
print("var is nil")
endBoolean(布尔)
1
2
3if type(var) == "boolean" then
print("var is a boolean")
endNumber(数字)
1
2
3if type(var) == "number" then
print("var is a number")
endString(字符串)
1
2
3if type(var) == "string" then
print("var is a string")
endTable(表)
1
2
3if type(var) == "table" then
print("var is a table")
endFunction(函数)
1
2
3if type(var) == "function" then
print("var is a function")
endThread(线程)
1
2
3if type(var) == "thread" then
print("var is a thread")
endUserdata(用户数据)
1
2
3if type(var) == "userdata" then
print("var is userdata")
end
特殊情况:区分整数和浮点数
从Lua 5.3开始,整数和浮点数被视为number类型的不同子类型。虽然type函数对于这两者都会返回"number",但你可以使用math.type来进一步区分它们:
1 | |
类型转换
Lua会在需要时自动进行一些基本的类型转换(如数字到字符串的转换)也称为类型提升或隐式转换。
隐式类型转换
字符串和数字:
Lua在需要时会在字符串和数字之间进行自动转换。当一个数字和字符串进行算术操作时,字符串会被尝试转换为数字。
print("123" + 1) -- 输出 124 (字符串"123"被转换为数字)当数字用于字符串上下文时,比如拼接操作,数字将被转换为字符串。
print(123 .. " apples") -- 输出 "123 apples" (数字123被转换为字符串)
布尔值:
在条件表达式中nil和false被视为假其他所有值(包括0和空字符串)都被视为真。
1
2
3if 0 then
print("0 is true in Lua")
end
注意事项:
- 避免假设:
在编写Lua代码时,避免过分依赖隐式类型转换,特别是在数据类型不明确的情况下。
明确的类型检查和转换可以使代码更可靠、更易于理解。 - 错误处理:
自动类型转换可能导致意外的结果,尤其是在处理外部数据或复杂的逻辑时。
因此,有时候显式检查和转换类型更为安全。
几个隐式类型转换的案例:
1 | |
显式类型转换
- 字符串到数字:
- 使用
tonumber()函数将字符串转换为数字。 - 如果转换失败(例如,字符串不是有效的数字表示),则返回
nil。1
2local num = tonumber("123") -- 转换成功,num为123
local fail = tonumber("abc") -- 转换失败,fail为nil
- 使用
- 数字到字符串:
- 使用
tostring()函数将数字转换为字符串。1
local str = tostring(123) -- str为"123" - 使用
string.char()ASCII码转为字符。1
2local str = string.char(72, 101, 108, 108, 111)
print(str) -- 输出 "Hello"
- 使用
- 布尔型 通常不需要转换
- 表(table)和函数(function)通常不需要转换
因为它们是复杂的结构或行为,而不是基本的数据类型。 - 对于 用户数据型(userdata) 和 线程型(thread) 类型,通常没有必要或方法进行转换,因为它们代表了特定于应用程序的数据和并发执行的线程。
注意事项:
- 有效性检查:
在进行显式类型转换时,应该注意检查结果是否有效(比如tonumber()是否返回了nil)。 - 类型安全:
显式类型转换增加了类型安全性,因为你明确指定了如何和何时进行转换。 - 转换的局限性:
显式类型转换有其局限性,不是所有类型的转换都有意义或可能。
3.2 变量与赋值
3.2.1 声明变量
Lua中的变量在首次赋值时被创建。Lua是动态类型语言,不需要类型声明。
1 | |
3.2.2 局部变量与全局变量
Lua中的变量可以分为局部变量和全局变量,它们的主要区别在于作用域和生命周期。
理解局部变量和全局变量的这些差异对于编写高效、可读性强和易于维护的Lua代码非常重要。
| 区别点 | 局部变量 | 全局变量 |
|---|---|---|
| 作用域 | 局部变量只在它被声明的代码块内有效。代码块通常是函数、循环或条件语句。 | 全局变量在整个Lua脚本中都是有效的,无论在哪里声明。 |
| 声明 | 使用local关键字声明如 local x = 10。 |
不使用local关键字,直接赋值即可如 x = 10。 |
| 内存管理 | 当代码块执行结束后,局部变量就会被释放。 | 全局变量存储在全局环境中,除非显式地设置为nil,否则不会被自动释放。 |
| 性能 | 使用局部变量可以提高程序的运行效率,因为它们存储在栈上,且访问速度更快。 | 频繁使用全局变量可能降低程序性能,并可能导致命名冲突和难以追踪的错误。 |
示例:
1 | |
总结:
- 使用建议:
通常建议尽量使用局部变量,这样可以避免意外的全局变量污染和命名冲突,同时提高代码的模块化和可维护性。 - 内存和性能:
局部变量在性能和内存管理方面更有优势,因为它们在不再需要时会被自动回收。 - 全局变量的谨慎使用:
尽管全局变量在某些情况下很有用(比如作为配置设置或共享数据),但应该谨慎使用,并且明确知道其作用域和生命周期。
注意:函数也可以算做变量,所以函数也有局部函数和全局函数的区分
3.3 控制结构
3.3.1 条件语句
if语句:语句是最基本的条件语句,用于当条件为真时执行代码块。
1
2
3if condition then
-- 执行条件为真时的代码
endelseif 和 else语句:
elseif用于添加额外的条件判断。else用于当所有条件都不满足时执行的代码块。1
2
3
4
5
6
7if condition1 then
-- 条件1为真时执行
elseif condition2 then
-- 条件2为真时执行
else
-- 所有条件都不为真时执行
end3.3.2循环
while循环
while循环会在给定条件为真时重复执行代码块。
1 | |
数值for循环
数值for循环使用一个计数器变量,该变量从初始值开始,每次循环增加固定的步长,直到达到终止值。
1 | |
泛型for循环
泛型for循环用于遍历表或数组。
1 | |
repeat…until 循环
repeat...until循环至少执行一次代码块,然后重复执行直到给定条件为真。
类似于别的语言的do…while
1 | |
终止循环break
用于提前终止循环。break可以用在for、while和repeat...until循环中,当执行到break时,循环将立即终止。
1 | |
没有continue!但是有goto
Lua中没有直接提供continue语句,这是一个在许多其他编程语言中用于跳过当前循环迭代并继续执行下一个迭代的语句。在Lua中,如果你需要实现类似continue的功能,你需要采用不同的方法来构造你的循环逻辑。
在Lua中,你通常可以通过在循环体内使用if和goto语句来模拟continue的行为。例如:
1 | |
从Lua 5.2开始,Lua引入了有限的goto语句,你可以使用goto与标签来实现类似continue的效果。
如上面的示例所示,goto continue跳到循环末尾的::continue::标签,从而开始下一次循环迭代。
3.3.3 逻辑运算与关系运算
逻辑运算符:
and(与):
当两个条件都为真时,结果为真。or(或):
当至少一个条件为真时,结果为真。not(非):
反转条件的真假。
关系运算符:
- == 相等
- ~= 不等
- <小于
- >大于
- >=大于等于
- <=小于等于
示例:
1 | |
短路求值:
Lua中的and和or运算符执行短路求值:
- **
and**:如果第一个条件为假,则不再评估第二个条件。 - **
or**:如果第一个条件为真,则不再评估第二个条件。
这可以用于编写更高效的代码,如在访问可能为nil的表项之前先检查表是否存在。
3.4 基本数据操作
3.4.1 数字
在Lua中,数字是一种非常基本的数据类型。
Lua中的数字类型(number)通常是以双精度浮点数形式表示的,尽管从Lua 5.3开始,整数也作为一个独立的子类型被引入。
下面我们将详细介绍Lua中数字的基本操作。
算术运算
- 加法 (
+): 计算两个数的和。 - 减法 (
-): 计算两个数的差。 - 乘法 (
*): 计算两个数的积。 - 除法 (
/): 计算两个数的商。 - 取模 (
%): 计算两个数相除的余数。 - 指数 (
^): 计算一个数的指数。
示例:
1 | |
注意:
Lua语言中没有++、--、+=、-=等操作符。
它没有包含这些在其他语言中常见的递增、递减和复合赋值操作符。
你需要显式地写出完整的赋值表达式
位运算
从Lua 5.2开始,语言内核引入了对位运算的原生支持。Lua 5.2及以后的版本提供了以下位运算符:
- 按位与 (
&) - 按位或 (
|) - 按位异或 (
~) - 按位非 (
~) - 左移 (
<<) - 右移 (
>>)
示例:
1 | |
数学计算函数
Lua的标准库提供了一系列用于数学计算的函数,包括:
math.abs(x): 返回x的绝对值。math.floor(x): 返回不大于x的最大整数。math.ceil(x): 返回不小于x的最小整数。math.sqrt(x): 返回x的平方根。math.max(x, ...): 返回所有参数中的最大值。math.min(x, ...): 返回所有参数中的最小值。math.random(): 生成一个在[0,1)区间的伪随机数。math.random(n): 生成一个从1到n的伪随机整数。math.random(m, n): 生成一个从m到n的伪随机整数。math.floor(x): 返回不大于x的最大整数(向下取整)。math.ceil(x): 返回不小于x的最小整数(向上取整)。math.modf(x): 返回x的整数部分和小数部分。
示例:
1 | |
Lua没有内置的四舍五入函数,但你可以通过math.floor或math.ceil函数结合加上0.5来实现四舍五入。
示例:
1 | |
练习题 3.4.1
题目 1: 最大值函数
编写一个Lua函数,接收一系列数字作为参数,并返回这些数字中的最大值。
1 | |
题目 2: 计算圆的面积
编写一个函数,接受一个圆的半径作为参数,并返回该圆的面积(使用公式:面积 = π * 半径^2)。
1 | |
题目 3: 斐波那契数列
编写一个函数,接受一个整数n,并返回斐波那契数列的第n个数。斐波那契数列的定义为:F(0)=0, F(1)=1, F(n)=F(n-1)+F(n-2)。
1 | |
题目 4: 检测素数
编写一个函数,检测一个给定的整数是否是素数(只能被1和自身整除的数)。
1 | |
题目 5: 数字倒序
编写一个函数,接受一个整数,并返回其数字倒序的整数。例如,给定123,返回321。
1 | |
3.4.2 字符串
定义
使用单引号、双引号或中括号定义字符串。
1 | |
连接
使用 .. 连接字符串。
1 | |
转义
如果你不使用长括号定义字符串,而是选择使用普通的单引号或双引号,那么需要使用反斜线 \ 来转义特定的字符。
这种方式类似于许多其他编程语言的字符串转义机制。
常见的转义序列:
- 换行符:
\n - 回车符:
\r - 制表符:
\t - 反斜线:
\\ - 单引号:
\'(当你的字符串用单引号包围时) - 双引号:
\"(当你的字符串用双引号包围时)
示例:
1 | |
长括号
如果你使用长括号定义字符串,就无需转义
Lua中的长括号(或称为长字符串)是一种特殊的语法,用于定义多行字符串或包含特殊字符的字符串,而不需要转义。长括号使用一对双方括号 [[...]] 来界定字符串。
它在处理多行字符串或需要保留原始格式的字符串时非常有用。
了解并熟练使用这一特性可以让处理文本数据在Lua中变得更加容易和直观。
长括号定义字符串的特点
- 多行字符串:
长括号非常适合定义包含多行文本的字符串。 - 无需转义:
在长括号内部,不需要转义引号或其他特殊字符,这使得包含复杂文本(如JSON或XML)的字符串更容易编写和阅读。 - 保留格式:
字符串的格式(包括空格、换行等)会被完全保留。
示例:
1 | |
这段代码中的 multiLineString 变量包含了一个多行字符串,其中的换行和空格都被保留了下来。
长括号的转义:
Lua还支持嵌套的长括号,这允许在字符串内部包含长括号。
这是通过在两边的方括号间添加相等数量的等号来实现的。
示例:
1 | |
在这个示例中,字符串由 [==[ 和 ]==] 包围,因此内部的 [[ 和 ]] 不会被解释为字符串的界定符,而是字符串内容的一部分。
格式化
Lua提供了强大的字符串格式化功能,类似于C#中的String.Format。
在Lua中,这是通过string.format函数实现的,它的使用方式类似于C语言中的printf函数。
string.format函数允许你创建一个格式化的字符串。它使用格式化字符串作为第一个参数,该字符串可以包含一系列的格式化指示符,后续参数将替换这些指示符。
常用的格式化指示符:
%s:格式化字符串%d或%i:格式化整数%f:格式化浮点数%.nf:格式化浮点数,n指定小数点后的位数- %x:16进制表示
示例:
1 | |
输出:
1 | |
在这个示例中,%s 被替换为字符串变量 name,%.1f 被替换为浮点数 version(保留一位小数),%d 被替换为整数 year。
其他常用操作
Lua的字符串库提供了许多有用的函数来处理字符串。以下是一些常用的函数:
string.len(s)
返回字符串s的长度。1
2local length = string.len("Hello")
print(length) -- 输出 5string.upper(s) 和 string.lower(s)
将字符串s转换为大写或小写。1
2print(string.upper("Hello")) -- 输出 "HELLO"
print(string.lower("Hello")) -- 输出 "hello"string.sub(s, i, j)
返回字符串s中从索引i到j的子串(包括索引i和j处的字符)。
如果j未指定,则返回从i到字符串末尾的子串。1
2local subStr = string.sub("Hello Lua", 2, 5)
print(subStr) -- 输出 "ello"string.gsub(s, pattern, replacement)
在字符串s中替换所有匹配pattern的部分为replacement。1
2local result = string.gsub("Hello Lua", "Lua", "World")
print(result) -- 输出 "Hello World"string.find(s, pattern)
在字符串s中查找pattern,返回找到的第一个匹配项的起始和结束索引。
如果未找到匹配项,则返回nil。1
2local start, finish = string.find("Hello Lua", "Lua")
print(start, finish) -- 输出 "7 9"string.match(s, pattern)
从字符串s中提取与pattern匹配的子串。1
2
3local date = "Today is 17/03/2023"
local d, m, y = string.match(date, "(%d+)/(%d+)/(%d+)")
print(d, m, y) -- 输出 "17 03 2023"string.gmatch(s, pattern)
全局匹配函数用于创建一个迭代器,该迭代器可以遍历字符串中所有匹配指定模式的子串。1
2
3for word in string.gmatch("Hello Lua World", "%a+") do
print(word)
endstring.rep(s , repeatTimes)
用于重复一个字符串指定次数,并返回结果。1
2local repeated = string.rep("Lua ", 3)
print(repeated) -- 输出 "Lua Lua Lua "string.reverse(s)
返回一个字符串的翻转string.dump(target)
函数用于将一个函数转换为一个字符串。
这个字符串包含了该函数的字节码表示。这通常用于序列化函数以便存储或传输,然后可以通过load函数重新加载并执行。使用场景:
- 序列化函数:用于保存函数的字节码,可以跨会话或网络传输。
- 调试目的:查看函数的内部字节码结构。
练习题 3.4.2
题目 1: 字符串反转
编写一个Lua函数,接受一个字符串作为参数,并返回这个字符串的反转。
1 | |
题目 2: 单词计数
编写一个Lua函数,统计并返回给定字符串中单词的数量。这里,你可以假设单词之间由空格分隔。
1 | |
题目 3: 字符串中的大写字母
编写一个Lua函数,接受一个字符串并返回该字符串中大写字母的数量。
1 | |
题目 4: 判断字符串是否是回文
编写一个Lua函数,检查一个字符串是否是回文(即正着读和反着读都相同)。
1 | |
题目 5: 字符串替换
编写一个Lua函数,替换字符串中的所有指定子串为另一个子串。
1 | |
3.4.3 函数
Lua中的函数极其灵活,可以用于各种高级编程模式,如闭包、高阶函数和回调。理解和熟练使用这些特性,将使你能够充分利用Lua的功能,编写出更为高效和可读的代码。
基础操作
定义函数:使用
function关键字。1
2
3function greet(name)
print("Hello, " .. name)
end调用函数:
1
greet("Lua")返回值:
Lua函数可以返回多个值。1
2
3
4
5
6
7
8
9
10function maxmin(a, b)
if a > b then
return a, b
else
return b, a
end
end
local max, min = maxmin(10, 5)
print(max, min) -- 输出 "10 5"当函数的参数只有一个字符串常量时,调用函数的()可以被省略。
例如:
1 | |
变长参数
Lua函数可以接受变长参数,通过...表示。
1 | |
table.pack 和 table.unpack 是两个处理变长参数或数组的有用函数。
table.pack
table.pack 用于将多个参数打包成一个表。
这在处理变长参数时尤其有用,因为它允许将所有参数捕获到一个表中,以便后续处理。
用法:
1 | |
示例:
1 | |
table.unpack
table.unpack 是 unpack 函数在 Lua 5.2 及更高版本中的等价函数(在 Lua 5.1 中仍然是 unpack)。
它用于将表中的元素作为多个返回值返回,这在将表中的值传递给期望多个参数的函数时非常有用。
用法:
1 | |
示例:
1 | |
组合使用
table.pack 和 table.unpack 可以结合使用,以在函数间传递变长参数列表。这对于编写可以接受任意数量参数的函数或将参数传递给另一个期望多个参数的函数非常有用。
示例:
1 | |
在这个示例中,multiply 函数接受一个因子和一系列数字,将每个数字乘以因子,然后使用 table.unpack 返回所有结果。sum 函数接受一系列数字并计算它们的总和。我们通过 table.pack 和 table.unpack 将参数从 multiply 传递到 sum。
高阶函数
在Lua中,函数可以作为参数传递给其他函数,或者作为返回值。
函数作为参数:
1 | |
返回函数:
1 | |
匿名函数
Lua支持匿名函数,这在编写一次性函数或传递给高阶函数时非常有用。
1 | |
尾调用
尾调用(Tail Call)是函数编程中的一个概念,指的是一个函数在其返回时直接调用另一个函数,而没有更多的操作。
尾调用是一种特殊的函数调用,因为在执行尾调用时,当前函数的执行环境(包括调用栈帧)可以被释放,因为所有的局部变量都不再需要了。
尾调用的示例:
1 | |
在这个例子中,函数 f 在返回时直接调用函数 g,而不做任何其他操作。这是一个尾调用的例子。
在 Lua 中,尾调用有特别的优化:尾递归优化。
如果一个函数的最后一个动作是调用另一个函数(包括它自己),Lua 会使用一种称为“尾调用消除”的技术,它可以让尾调用不使用任何额外的栈空间,从而避免增加额外的栈帧。这意味着尾递归函数可以进行大量的递归调用而不会溢出栈。
需要注意的时,函数的最后一个操作必须只是调用另一个函数才算尾调用,有其他操作的就不算。
比如以下的几个例子就不算:
1 | |
练习题 3.4.3
题目 1:阶乘函数
编写一个Lua函数,计算并返回一个给定整数的阶乘。
1 | |
题目 2:高阶函数映射
编写一个Lua函数,接受一个函数和一个数组,返回一个新数组,该数组是将原始数组中的每个元素通过给定函数转换后的结果。
1 | |
题目 3:闭包计数器
编写一个Lua函数,返回一个闭包,该闭包每次被调用时返回一个递增的整数。
1 | |
题目 4:组合函数
编写一个Lua函数,它接受两个函数f和g作为参数,并返回一个新的函数。这个新函数在被调用时,应先将其参数传递给g,然后将g的结果传递给f,最后返回f的结果。
1 | |
题目 5:组合函数
编写一个Lua函数,接受任意数量的参数,并返回它们的总和。
1 | |
3.4.4 日期与时间
在 Lua 中处理日期和时间主要依赖于 os 库中的 os.time 和 os.date 函数。这些函数提供了获取和格式化日期和时间的能力。
使用 os.time 和 os.date,你可以方便地在 Lua 中处理日期和时间,无论是进行时间计算还是格式化输出日期和时间。
os.time
os.time 函数用于
- 获取当前时间
- 将日期转换为时间戳(自 1970 年 1 月 1 日以来的秒数)。
参数:表(可选):
一个描述日期和时间的表。
这个表可以包含年(year)、月(month)、日(day)、小时(hour)、分钟(min)、秒(sec)等字段。
如果没有提供表,os.time 返回当前时间的时间戳。
返回值:时间戳:
一个数字,表示自 Unix 纪元(1970 年 1 月 1 日)以来的秒数。
代码案例:
获取当前时间的时间戳:
1 | |
将特定日期转换为时间戳:
1 | |
os.date
os.date 函数用于
- 格式化时间戳为可读的日期和时间字符串
- 返回一个包含日期和时间信息的表
参数:
- 格式字符串(可选):
指定输出格式的字符串。默认为%c,表示本地日期和时间的完整格式。os.date的格式字符串遵循 C 语言中strftime函数的规则。
常用的格式指示符包括- %a:缩写的星期几名称(如 Wed)
- %A:完整的星期几名称(如 Wednesday)
- %b:缩写的月份名称(如 Sep)
- %B:完整的月份名称(如 September)
- %c:日期和时间(如 09/16/98 23:48:10)
- %d:月份中的第几天(01-31)
- %H:24小时制的小时数(00-23)
- %I:12小时制的小时数(01-12)
- %j:年份中的第几天(001-366)
- %m:月份(01-12)
- %M:分钟数(00-59)
- %p:AM 或 PM
- %S:秒数(00-59)
- %U:年份中的第几周,以周日为一周的第一天(00-53)
- %w:星期几(0-6),星期天为0
- %W:年份中的第几周,以周一为一周的第一天(00-53)
- %x:日期(如 09/16/98)
- %X:时间(如 23:48:10)
- %y:年份的最后两位数字(00-99)
- %Y:完整的年份(如 1998)
- %Z:时区名称(如果不存在,则返回空字符串)
- **%%**:百分号自身
- 时间戳(可选):
要格式化的时间戳。如果没有提供,os.date使用当前时间。
返回值:
格式化的日期/时间字符串 或 日期/时间表,取决于格式字符串。
代码案例:
获取并打印当前日期和时间:
1 | |
以特定格式打印日期和时间:
1 | |
获取当前时间的表:
1 | |
练习题
题目 1:计算两个日期之间的天数差
描述:
编写一个 Lua 程序,计算两个给定日期之间的天数差。
你需要使用 os.time 函数将日期转换为时间戳,然后计算它们之间的差异,并将其转换回天数。
1 | |
预期输出:Days between: 30
题目 2:格式化当前日期和时间
描述:
使用 os.date 函数,编写一个 Lua 程序来格式化并打印当前日期和时间,格式为 "YYYY-MM-DD HH:MM:SS"。
预期输出:Current date and time: 2021-09-21 12:34:56
题目 3:计算特定日期是星期几
描述:
编写一个 Lua 程序,计算给定日期是星期几。例如,输入 {year=2021, month=9, day=21} 应该返回该日期是星期几。
1 | |
预期输出: The day of the week is: Tuesday
题目 4:创建一个简单的倒计时器
描述:
编写一个 Lua 程序,创建一个简单的倒计时器。
程序应该接受一定数量的秒数,然后每秒钟递减,直到达到零。
1 | |
预期输出:
1 | |
3.5 代码规范
3.5.1 命名规范
Lua作为一种灵活的编程语言,并没有官方强制的命名规范,但遵循一些通用的命名约定可以使你的代码更加清晰和易于维护。以下是一些推荐的Lua编程中的命名规范:
| 代码内容 | 命名方法 | 示例 |
|---|---|---|
| 局部变量 | 小驼峰式命名 | local function doSomethingImportant() end |
| 全局变量 | 大驼峰式命名 | GlobalVariable = 20 |
| 常量 | 全大写,并用下划线分隔 | local MAX_SIZE = 100 |
| 表和模块 | 大驼峰式命名 | local Person = {} |
任何变量,函数或标识符都不能与lua的保留字同名
lua保留字如下:
| local | function | return | end | nil |
|---|---|---|---|---|
| if | elseif | else | true | false |
| and | or | not | then | break |
| for | in | repeat | do | while |
| until | goto |
3.5.2 注释
单行注释
单行注释以两个连字符--开始。从这两个连字符开始到行末的所有内容都被视为注释,不会被Lua执行。
示例:
1 | |
在这个示例中,第一行完全是注释,而第二行中的local x = 10是代码,-- 这也是一个单行注释是注释。
多行注释
多行注释使用一对长括号--[[ 和 ]]来界定。所有在这两个标记之间的内容都被视为注释。
示例:
1 | |
在这个示例中,从--[[开始到]]结束的部分是多行注释。
注释的最佳实践
- 清晰性:
注释应该清晰地解释代码的意图和行为,而不是简单地描述代码是做什么的。 - 更新:
确保随着代码的变化更新注释,以防止出现误导。 - 适度:
适当地使用注释,过多的注释可能会使代码难以阅读,而过少则可能使代码难以理解。
注释是编写清晰、可维护代码的重要部分。
合理地使用注释可以帮助你和其他开发者更好地理解和维护代码。
4. 表
Lua中的表(table)是一种非常灵活的数据结构,它实际上是一个关联数组(associative array)。表可以用作普通的数组、字典、集合,甚至是对象。在Lua中,表是唯一的复合数据类型,用于构建各种复杂的数据结构。
4.1 基础操作
- 创建
local myTable = {}
使用大括号{}创建一个新表 - 插入
table.insert(t, [pos,] value)
向表t中的指定位置pos插入值value。如果未指定pos,则默认插入到表的末尾。 - 移除
table.remove(t, [pos])
从表t中移除位于位置pos的元素。如果未指定pos,则默认移除表中的最后一个元素。 - 排序
table.sort(t, [comp])
对表t进行排序。如果提供了比较函数comp,则使用该函数确定元素顺序。 - 连接成字符串
table.concat(t, [sep [, i [, j]]])
连接表t中的字符串元素,从索引i到j,使用字符串sep作为分隔符。 - 解包
table.unpack(t, [i [, j]])
返回表t中从索引i到j的所有元素。等同于Lua 5.1中的unpack函数。 - 打包
table.pack(...)(Lua 5.2+)
将传入的参数封装到一个新表中,并返回这个表。
4.2 表用作数组
Lua表可以用作数组,索引通常从1开始。
初始化:
1 | |
遍历:
使用ipairs遍历数组风格的表:
1 | |
多维表:
表可以嵌套,用于创建多维数组或更复杂的数据结构。
1 | |
取长运算符:
Lua中的#运算符用于获取表的长度,它主要适用于序列(数组部分的表),即索引连续的表。
1 | |
在这个例子中,#arr 返回数组 arr 中的元素数量。
注意事项:
- 当表被用作数组时,
#运算符返回到第一个nil元素之前的元素数量。- 对于非数组(非连续索引)的表,
#的行为可能是未定义的,应避免在这种表上使用#。
4.3 表用作字典
表也可以用作键-值对集合,类似于字典或哈希表。
初始化:
1 | |
遍历:
使用pairs遍历字典风格的表:
1 | |
练习题 4.1
题目 1: 表的合并
编写一个Lua函数,接受两个表作为参数,返回一个新表,该表是将这两个表的元素合并在一起。
1 | |
题目 2: 键值反转
编写一个Lua函数,接受一个表作为参数,返回一个新表,该表的键和值是原表的值和键。
1 | |
题目 3: 表的深度拷贝
编写一个Lua函数,实现对表的深度拷贝,确保原表和新表完全独立,修改一个不会影响另一个。
1 | |
题目 4: 表中最大值的键
编写一个Lua函数,找出数值型表中最大元素的键。
1 | |
题目 5: 表元素的计数
编写一个Lua函数,接受一个表作为参数,返回一个新表,该表记录了原表中每个元素出现的次数。
1 | |
4.4 元表与元方法
4.4.1 元表(Metatable)
在Lua中,元表是一种特殊的表,它为另一个表(称为目标表)定义了特殊的行为。
元表可以改变目标表的行为,包括算术操作、比较操作、索引操作等。
注意:元表和目标表可以是一个表,这也是利用元表来模拟集成派生的关键
设置元表:
使用setmetatable函数为表设置元表:
1 | |
获得元表:
使用getmetatable函数获取目标表的元表
4.4.2 元方法(Metamethod)
元方法是元表中的特殊键,用于定义某些操作的行为。
当对表进行特定操作时,如果该表有元表,并且元表中有相应的元方法,那么这个元方法就会被调用。
算数元方法
可用于表的算数运算符重载
__add+(加法)__sub-(减法)__mul*(乘法)__div/(除法)__mod%(取模)__unm-(取负)__pow^(幂运算)__idiv://(整除)
位运算元方法
可用于表的位运算符号重载
__band:&(位与)__bor:|(位或)__bxor:~(位异或)__bnot:~(位非)__shl:<<(位左移)__shr:>>(位右移)
关系元方法
可用于表的关系运算符重载
__eq(等于)__lt(小于)__le(小于等于
其他元方法
__index:
当访问表中不存在的键时调用。可以是一个函数或另一个表__newindex:
当向表中不存在的键赋值时调用。__metatable:
用于保护元表,防止外部访问和修改。__call:
当Lua尝试调用一个表时调用。__tostring:
改变表转换为字符串时的行为。__len:
改变获取表长度(#操作符)的行为。__concat:
重载连接操作符(..)__gc:
垃圾收集(在表被回收时调用)
重载析构函数__mode:
设置弱表的行为__close:
关闭操作(Lua 5.4中引入)
类似于Go语言的defer语句,即在离开局部作用域时自动执行某些操作。
4.4.3 绕过元表和元方法
有一些Lua语言内置的基础函数,它们提供了直接操作表的能力,绕过了元表(metatable)的拦截机制。
这些函数是Lua标准库的一部分,提供了对表的底层访问。
- **
rawset**:
用于直接设置表中的值,绕过元表中的__newindex元方法。 - **
rawget**:
用于直接从表中获取值,绕过元表中的__index元方法。 - **
rawequal**:
检查两个值是否相等,不触发元表中的__eq元方法。 - **
rawlen**:
返回表的长度,不触发元表中的__len元方法。
示例:
使用__index和__newindex
1 | |
练习题 4.4
题目 1:创建一个只读表
编写一个Lua函数,该函数接收一个表,并返回一个新的表,新表是只读的,任何试图修改它的操作都会抛出错误。
1 | |
题目 2:实现一个简单的向量类
使用表和元表来模拟一个简单的二维向量类,支持向量的加法和字符串表示。
如果这题暂时不会,可以学完下面的表用作对象4.5.1后再来看看
1 | |
题目 3:自定义迭代器
创建一个表和相应的元表,使得该表能通过自定义的迭代器进行迭代。
1 | |
题目 4:表的算术操作
编写元方法来使得两个表可以进行算术运算,如两个表的元素相加。
1 | |
4.5 表用作对象
在Lua中,表也可以用作类和对象。
你可以在表中存储函数以及数据,从而模拟面向对象编程的功能。
Lua本身不具有内置的类系统
4.5.1 类的实现
“类”可以通过一个表来定义:
1 | |
这个案例中需要注意的点有:
字段初始化:
在Lua中,类的字段通常是在构造函数中进行的。
不过也可以在类的定义中初始化。构造函数:
Lua本身没有给我们提供构造函数,new方法实际上是我们自己定义的,这是模拟面向对象编程中类的构造器的标准做法。__index元方法:
将MyClass.__index设置为MyClass本身,使得当尝试访问类实例中不存在的字段或方法时,Lua会在MyClass表中查找。
正确设置__index元方法对于类的方法能够正确工作是至关重要的。__gc元方法:
设置__gc元方法相当于实现了类的析构函数类方法的定义:
- 类内部方法定义:
method1在类定义的大括号内定义。
这种方法使类定义更紧凑,但可能会使得类定义过于庞大,特别是当方法较多时。 - 类外部方法定义:
method2和method3在类定义外部定义。
这种方式使得每个方法更加独立,但可能会分散类的定义。
- 类内部方法定义:
类方法的调用:
点
.调用方式:
当使用点.调用方法时,需要显式地传递self参数。冒号
:调用方式:
当使用冒号:调用方法时,Lua会自动将调用该方法的表作为self参数传递给该方法。self参数
在Lua中,self是一个用于面向对象风格编程的关键字。
它在方法定义和调用中发挥着重要作用,类似于其他编程语言(如Python的self或Java和C++的this)中的自引用。self允许在方法内部访问和操作对象的状态。它提供了一种直观的方式来实现对象的方法,使得Lua代码更加易于理解和维护。尽管Lua没有内置的面向对象系统,但通过使用表、元表和self参数,Lua可以非常灵活地模拟面向对象的行为。注意:
在Lua中,self不是一个保留字,而是按照惯例使用。你可以选择使用其他名字,但self是最常用的。
实例化:
使用MyClass:new()来创建类的实例。
这种方式模拟了面向对象语言中的对象创建过程。
4.5.2 静态方法与静态属性
想要在Lua中实现静态类,静态方法,静态属性,也都是靠用表进行模拟。
我们看一下下面的案例,就能体会到其中的奥秘:
1 | |
StaticClass类创建了两个实例:instance1与instance2
此时两个实例表内并没有count,输出时是根据__index去类表中取的count值
所以三个值都为类表中的静态值,就是0- 实例表
instance1调用了实例方法instanceMethod
它是用self.count =在实例表instance1中增加了字段cout
而这个cout值=类表StaticClass的cout值+1
所以此时:- 类表中的静态
cout值还是0 - 实例表
instance1内有了自己的cout,值是1 - 实例表
instance2内仍然没有cout,依然是从类表取,所以也是0
- 类表中的静态
- 实例表
instance1用”.”调用了方法staticMethod,且没有传入self参数
所以实际上是通过__index去类表中调用了staticMethod方法
这样就模拟了静态方法
所以此时:- 类表中的静态cout值变为1
- 实例表
instance1自己的cout值是1 - 实例表
instance2内也还没有cout,依然是从类表取,所以也是1
- 类表
StaticClass用“.”调用方法staticMethod,且没有传入self参数
实际执行和上一步基本一样,只是少了从instance1的__index找到staticMethod这一步
所以此时:- 类表中的静态cout值变为2
- 实例表
instance1自己的cout值是1 - 实例表
instance2内也还没有cout,依然是从类表取,所以也是2
- 实例表
instance2调用了实例方法instanceMethod
它是用self.count =在实例表instance2中增加了字段cout
而这个cout值=类表StaticClass的cout值+1
所以此时:- 类表中的静态cout值为2
- 实例表
instance1自己的cout值是1 - 实例表
instance2内有了自己的cout,值是3
由上面的过程分析可知,lua用模拟的方式实现了静态方法和静态属性,但本质上还是有所差异。
需要在使用的时候小心避免出现实例和静态混淆的情况。
要在Lua中清晰地模拟静态方法和属性,最好遵循一些指导原则:
明确区分静态属性和实例属性:
静态属性应该定义在类表中,实例属性应该只在实例创建时(构造函数中)定义。避免在实例方法中修改静态属性:
实例方法应该只操作实例属性。
如果需要修改静态属性,应该通过显式地引用类表来操作。使用明确的方法调用方式:
静态方法只通过
类表.方法()的方式调用。实例方法应该通过实例调用。
这有助于防止误操作静态属性。
4.5.3 继承与派生
lua的继承也是用元表来模拟实现的
继承派生案例:
1 | |
这个案例中需要注意的点有:
- 子类构造函数:
在子类的new函数中,使用了BaseClass:new()来创建一个基类实例,并将其元表设置为DerivedClass,这样子类实例既拥有基类的特性又拥有子类的特性。 - 继承基类:
通过setmetatable(DerivedClass, {__index = BaseClass}),DerivedClass继承了BaseClass。
这意味着当在DerivedClass中查找不存在的字段时,Lua会在BaseClass中继续查找。 - Base:
在Lua中,没有像某些其他面向对象语言(如C#或Java)中那样的内置base或super关键字来直接引用父类。
但是,你仍然可以访问和调用基类(父类)的方法,即使在子类中有同名的方法。
这可以通过直接访问基类的方法实现。
注意:你必须使用基类表.基类方法(self)的方法来调用基方法
通过这种方式,我们也可以用lua写出接口/抽象类,虚方法的模拟。因为原理大同小异,我们就只提供接口的模拟案例。
接口模拟案例:
1 | |
同样的lua也可以通过模拟去实现多继承。
案例如下:
1 | |
其中的私有表并不是必须的,直接将私有属性和方法散写在方法内作为局部变量也可以达成一样的闭包效果
4.5.4 私有性
Lua中没有权限关键字(public,privte,protect等)。Lua的作者认为,如果不想访问一个对象的内容,那别访问就是了,比如在私有名称前加上下划线”_”,这样就能看出来是私有属性,别去访问就好。
不过如果一定想要实现私有性,是可以通过lua灵活的语言特性来模拟的。
私有性有很多种不同的方法可以模拟。
闭包模拟
私有性可以通过闭包(闭包是函数和函数所能访问的词法作用域的组合)来实现。
我们可以定义一个函数,这个函数内部有两个表。
- 私有表用来存储对象的私有属性或方法。
- 公有表用来存储对象的公有属性或方法。
最后返回共有表作为整个对象的代理或接口。
这样因为函数的闭包性质,私有表的内容就无法访问到了。就成功的模拟实现了私有性。
1 | |
但是使用这种方法进行私有性模拟的对象想要再实现继承派生就需要再做额外的模拟操作了。建议在不需要继承派生的对象上使用。
对偶表示
对偶表示的原理是:
把一个对象的私有属性和方法都存储到一个表中,然后再把这个表当作值,这个对象当作键,存储到一个类外的表中。
案例如下:
1 | |
这样做,并不能真正防止其他代码直接访问或修改这些数据。这种方法确实提供了一定程度的封装,因为它防止了直接通过对象实例访问或修改私有数据,但这并不是真正的私有性,因为外部表本身仍然是全局可访问的。
而且必须注意的是:
一旦我们将实例作为外部私有数据存储表的键,那么它的GC将无法自动生效。
因此需要注意内存管理,特别是在删除实例时,也应从 外部私有数据存储表中移除相应的条目以避免内存泄露。
练习题 4.5
创建一个lua文件,并在该文件中编写代码以满足以下要求:
- 定义一个简单的类和实例
定义一个名为Car的类,它有两个属性:make(制造商)和year(年份)。还要定义一个名为new的方法来创建新实例,并初始化这些属性。 - 实现一个实例方法
给Car类添加一个名为getAge的方法,该方法返回车辆的年龄。假设当前年份为2023。 - 静态属性和静态方法
为Car类添加一个静态属性totalCars,用于跟踪创建的车辆总数。同时添加一个静态方法getTotalCars,返回创建的车辆总数。 - 继承
创建一个ElectricCar类,它继承自Car类,并添加一个额外的属性batterySize。 - 多态性
为ElectricCar类重写getAge方法,使其在返回年龄的同时还输出一条消息表明这是一辆电动车。
1 | |
5. 代码组织(环境,模块,包)
我们接下来学习Lua中的环境、模块和包。
这是Lua编程中非常重要的一部分,它关系到如何组织和结构化大型应用程序。
5.1 环境
在Lua中,环境(Environment)是一个非常重要的概念,它涉及到变量的作用域和存储。Lua使用环境来保存变量和函数,这对于编写模块化和可重用的代码非常重要。
环境的具体作用:
- 作用域管理:
Lua中的每个函数都有自己的环境,用于保存该函数中定义的局部变量。 - 全局环境:
Lua脚本开始执行时,有一个默认的全局环境,所有全局变量都存储在这里。 - 避免冲突:
通过使用不同的环境,可以避免变量名冲突,特别是在大型项目或多模块程序中。
5.1.1 全局环境(_G)
原理
从语法层面讲,Lua只要是不带local关键字的变量,就是全局变量。但实际上,lua并没有真正意义上的全局变量,它仍然是在用表来模拟实现全局变量。
- 真的全局变量:
当你声明了一个全局变量后,它在编译时就会存储在一个全局作用域中。
无论是声明前的代码,还是声明后的代码都应该可以访问的到。 - Lua用表模拟的全局变量:
将你声明的全局变量存在一个特殊的表中。
你可以动态地添加、修改或删除全局变量。
而在你声明全局变量前的代码中是无法访问到这个全局变量的
(因为它根本还没放进那个特殊的表中!)
Lua将所谓的“全局变量”保存在一个称为全局环境(global environment)的普通表中。
这个表是叫_G。_G是一个特殊的表,在Lua程序启动时,_G被自动创建,它本质上是全局环境的一个表示。
当你定义一个不带local关键字的变量时,这个变量就会成为_G表的一个成员。
应用
访问全局变量:
你可以通过_G[变量名]的方式来访问全局变量。
当然调用声明过的全局变量时可以省略_G而直接使用全局变量名调用。
这种方式主要是为了调用具有动态名称的全局变量1
2
3
4
5
6-- 动态生成变量名
local varName = "globalVar"
-- 使用_G来设置全局变量
_G[varName] = "这是一个动态创建的全局变量"
-- 使用相同的方式访问这个全局变量
print(_G[varName]) -- 输出: 这是一个动态创建的全局变量避免污染:
_G的存在可以帮助你识别和避免全局变量污染。
在复杂的应用中,不小心创建了意料之外的全局变量是很常见的问题。
我们可以通过设置_G表的元表来禁止定义或访问尚不存在的全局变量:1
2
3
4
5
6
7
8
9
10
11
12
13
14setmetatable(_G, {
__newindex = function(_, n)
error("试图定义未知的全局变量 " .. n, 2)
end,
__index = function(_, n)
error("试图访问未定义的全局变量 " .. n, 2)
end,
})
rawset(_G, "A", 1) -- 使用rawset绕过元表定义新全局变量
print(A) -- 输出:1
A = 10
print(A) -- 输出:10
B = 20 -- 报错:试图定义未知的全局变量这种操作叫做严格模式
枚举全局变量:
你可以遍历_G来查看程序中定义的所有全局变量。
这对于调试和代码审查特别有用。
例如如下代码就是直接通过访问_G表来获取全部的全局变量,并打印出来:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50A = 1
B = 2
C = "C等于3"
for n in pairs(_G) do
print(n..":"..tostring(_G[n]))
end
--[[
以下为输出结果:
table:table: 0000000000f39b10
_G:table: 0000000000f36c30
rawlen:function: 0000000065b9cea0
assert:function: 0000000065b9d980
collectgarbage:function: 0000000065b9d330
arg:table: 0000000000f3a050
dofile:function: 0000000065b9d900
utf8:table: 0000000000f39c50
_VERSION:Lua 5.4
rawset:function: 0000000065b9cdf0
loadfile:function: 0000000065b9d830
load:function: 0000000065b9d730
B:2
A:1
setmetatable:function: 0000000065b9d560
rawget:function: 0000000065b9ce50
io:table: 0000000000f3a090
debug:table: 0000000000f39cd0
package:table: 0000000000f38570
pcall:function: 0000000065b9ca70
select:function: 0000000065b9cb20
rawequal:function: 0000000065b9cf00
warn:function: 0000000065b9cf50
math:table: 0000000000f39bd0
tonumber:function: 0000000065b9cbc0
print:function: 0000000065b9cff0
ipairs:function: 0000000065b9d0e0
os:table: 0000000000f39c90
error:function: 0000000065b9d2b0
require:function: 0000000000f384f0
C:C等于3
pairs:function: 0000000065b9d610
xpcall:function: 0000000065b9c970
next:function: 0000000065b9d130
getmetatable:function: 0000000065b9d8a0
type:function: 0000000065b9ca10
string:table: 0000000000f3a010
tostring:function: 0000000065b9caf0
coroutine:table: 0000000000f39800
]]你会发现,输出的结果除了有我们定义的全局变量A,B,C外,还有很多Lua自身的方法和表,这些都是全局环境的一部分。
5.1.2 局部环境(_ENV)
_ENV是Lua 5.2及以上版本引入的一个新概念。
它代表了当前代码块的环境。每个函数都有自己的_ENV,用于查找和存储变量。
通过改变_ENV,你可以更改函数的环境,使其访问不同的变量集合。
在Lua 5.2及以上版本中,_ENV取代了旧版本中的setfenv和getfenv功能。
原理
_ENV本质上仍然是一个表。
它默认指向全局环境_G,所以它最初包含所有全局变量。
但是,_ENV本身是可以更改的,可以指向任何表。编译器会在编译所有代码前,在外层给每个函数创建局部变量
_ENV
通常在函数定义时就确定,除非显式修改它。所有在函数内的自由名称
(就是未在局部环境中声明的变量
var x,实际上就是函数外部定义的全局变量)会被编译器自动设置为
_ENV.自由名称
其实就是从_ENV表指向_G表从而去全局变量中寻找了_ENV遵循通常的定界规则
我们可以根据这个特性,让多个函数共享一个公共环境。
或是在一个函数内创造多个局部环境函数作用域:
在Lua中定义的每个函数都有自己的作用域。_ENV作为当前环境的引用,也受到这些作用域规则的约束。
这意味着在一个函数内部改变_ENV只影响该函数及其内部定义的函数。比如:
1
2
3
4
5
6local function test()
_ENV = { print = print }
print("Hello") -- 正常输出
end
test()
print("Hello") -- 出错,因为全局环境的print在test函数外不可访问这里,函数
test内部的_ENV被修改,仅在函数内有效。
一旦离开函数,_ENV的改变不会影响外部环境。代码块作用域:
Lua中的局部变量(使用local关键字定义的变量)在它们被定义的那个代码块中有效。
同样,如果在一个代码块中设置了_ENV(作为局部变量),它只会影响该代码块。例如各种循环语句的代码块中
比如:
1
2
3
4
5for i = 1, 2 do
_ENV = { print = print }
print(i) -- 正常输出
end
print("Done") -- 出错,因为全局环境的print在循环外不可访问在这个循环内,
_ENV被修改了,但这种修改只在循环内部有效。**全局和局部
_ENV**:
如果_ENV被定义为全局变量(没有使用local关键字),它会影响所有没有自己局部_ENV的代码。
如果在函数或代码块中用local _ENV = ...定义了_ENV,那么这个新的环境只影响当前作用域。
比如:1
2
3
4
5
6do
local _ENV = {_G = _G}
print = function(s) _G.print("Modified:", s) end
print("Hello") -- 输出 "Modified: Hello"
end
print("Hello") -- 输出 "Hello"在这个代码块内,
_ENV被局部化和修改,影响仅限于这个代码块。
应用
控制代码禁止使用全局变量
因为_ENV默认是指向_G的,如果我们将它设为nil,则后续局部环境中就无法再直接访问全局变量了。
案例如下:1
2
3
4A = 10 -- 声明全局变量A
local print = print -- 声明局部变量print函数=_G中的print函数
_ENV = nil -- 设置局部环境指向nil
print(A) -- 此时的print是局部变量,A无法访问,会报错绕过局部声明的变量
和_G一样,可以直接获取全局变量
案例如下:1
2
3
4
5A = 10
local A = 20
print(_ENV.A) -- 输出:10
print(_G.A) -- 输出:10
print(A) -- 输出:20建立新环境实现沙盒(重点)
通过设置不同的_ENV,可以为不同的函数或代码块创建隔离的环境,这对于执行安全的脚本和模块化编程非常有用。
有两种方法可以实现沙盒:_ENV等于包含_G的新表
实现方法如下:1
2local newEnv = {_G = _G}
_ENV = newEnv这种方法的特点是:
- 提供了对全局环境的直接访问。
- 可以通过
_ENV._G访问和修改全局环境。 - 更改
_ENV._G中的内容实际上会改变全局环境_G。
继承了
_G的新表
实现方法如下:1
2local newEnv = setmetatable({}, {__index = _G})
_ENV = newEnv这种方法的特点是:
- 任何在新环境中未定义的变量都会通过
__index元方法回退到全局环境_G。 - 更改新环境中的变量不会影响
_G中的相应变量。
- 任何在新环境中未定义的变量都会通过
在比较这两种方法时,首先要考虑的是您对沙盒环境的需求:
如果需要完全隔离的环境,第二种方法(继承_G)更合适。
如果需要在沙盒环境中保留对原始全局环境的修改能力,第一种方法(包含_G的新表)可能更适合。
5.2 模块
在Lua中,模块是一种将代码组织成独立单元的方式。
模块通常包含函数、变量和其他Lua结构,可在其他Lua脚本中重复使用。
模块的作用:
- 代码重用:模块化编程允许重复使用代码,减少重复工作。
- 命名空间管理:模块帮助避免命名冲突,因为每个模块有自己的命名空间。
模块是Lua中实现代码封装和重用的重要机制,有助于创建结构清晰、易于维护的代码库。
直白的来讲,一个模块就是一些代码,这些代码可以通过函数require加载,然后创建并返回一个表。这个表就像是某种命名空间,其中定义的内容是模块中导出的东西,比如函数和常量。
5.2.1 创建模块
创建模块有两种方法:
方法一:
- 创建一个表:
表将作为模块的主体,包含模块的所有功能。 - 添加功能:
向这个表中添加函数、变量等。 - 返回这个表:
最后,使用return语句返回这个表,使其成为模块的导出。
案例:
1 | |
方法二:
- 定义功能:
把所有的函数和属性都定义为局部变量 - 构建表并返回:
创建一个表,将前面的功能全部装入此表中,然后返回此表
案例:
1 | |
这两种方法纯粹写法不一样,其他基本上都相同。
第二种写法可以让模块内的变量名称和模块外使用时的名称不一致,但除非特殊需求,否则还是保持一致比较好。
你还可以结合我们之前5.1环境的相关内容来编写模块,比如说禁止模块内更改全局变量,在模块内创建新局部环境制造沙盒等功能。
5.2.2 使用模块
加载模块
在其他Lua脚本中,你可以使用require函数来加载并使用模块。
案例:
1 | |
原理如下:
当调用require函数时
- 首先在表
package.loaded中检查模块是否已被加载。- 若模块已被加载过:
不会运行任何新代码,返回之前已经加载的同一个值。
- 若模块已被加载过:
- 搜索具有
package.path指定模块名的lua文件- 若找不到lua文件:
搜索具有package.cpath指定的相应名称的C标准库
找到后由package.loadlib加载并返回结果- 若再找不到就报错
- 若找不到lua文件:
- 找到对应lua文件后,用函数
loadfile将其加载,返回一个加载器loader作为结果 - 将加载结果返回,并保存在
package.loaded中
require 函数根据 package.path 和 package.cpath 变量来确定加载模块和包的路径。这些路径不是固定的,而是取决于系统上的 Lua 配置。
通常,这些路径会包括:
- Lua 安装目录
- 当前工作目录
- 以及其他一些标准位置。
可以在 Lua 脚本中运行时修改这些路径。
例如:
1 | |
;是目标路径的分隔符
可以增加多个目标路径按顺序寻找。?.lua和?.so是占位符
Lua 在搜索文件时会将模块名替换到这些位置。
通过调整这些变量,可以自定义 Lua 在 require 函数被调用时查找模块的位置。
模块在任何情况下只加载一次,如何处理冲突的加载,取决于模块本身,详见下面的init文件介绍
卸载模块
Lua中没有直接卸载模块的内置功能。但可以通过从package.loaded表中移除对应模块的引用来间接实现。
例如,要卸载一个名为myModule的模块,可以这样做:
1 | |
5.2.3 子模块与包
模块,子模块,包这三个概念都是Lua用来细分代码功能,清晰代码结构的。
他们分别从物理和抽象两方面做到了这点:
模块,子模块,包,子包的概念
物理方面
- 包,就是文件夹
- 模块,就是lua代码文件
- 包的子模块,就是某个文件夹下的所有lua代码文件
- 包的子包,就是文件夹中的文件夹
- 模块的子模块,在物理层面上没有意义
抽象方面
Lua支持具有层次结构的模块名,通过.来分割名称中的层次。例如:mod.sub。
无论你物理层面要怎么组织lua代码文件和文件夹,最终在代码抽象层面都会变成命名空间的层级关系。
命名空间层级关系:
- 顶级命名空间:
Lua的全局环境(_G)可以被看作是最顶级的命名空间,所有全局变量和函数都属于这个命名空间。 - 包:
每个包构成一个独立的命名空间。包内的模块通常通过包的名称来访问,这有助于避免不同包之间的命名冲突。 - 模块:
每个模块文件也创建了一个命名空间。模块内定义的函数、表和其他变量只在该模块内可见,除非它们被显式地导出。 - 子模块/子包:
在包内部,可以有更细粒度的命名空间划分,如子模块或子包。这些子命名空间进一步组织和封装了代码,有助于维护大型项目。
这样做的作用有:
- 避免冲突:
通过命名空间,相同名称的变量或函数可以在不同的模块中独立存在,避免相互干扰。 - 代码组织:
清晰的命名空间结构使代码更加模块化,便于理解和维护。 - 重用性和封装:
良好的命名空间设计提高了代码的重用性和封装性,有助于构建可维护和可扩展的应用程序。
init.lua文件
从Lua语言的视角来看,同一个包的子模块没有显示的关联。
加载一个模块并不会自动加载它的任何子模块。
同样的,加载一个子模块也不会自动的加载它的付模块。
如果想实现自动加载和处理依赖关系,需要我们自己在包中实现。
一般可以在包中的init.lua实现
当你使用require加载一个包(文件夹)而不是一个单独的Lua文件时,Lua会默认寻找该文件夹中的init.lua文件作为入口点。
它通常用于初始化包,设置包内所需的各种条件,比如加载包内的模块、设置包级别的变量、执行初始化代码等。
假设有一个包结构如下:
1 | |
当你执行require("mylib")时,Lua实际上会加载并执行mylib目录下的init.lua文件。
假设mylib的init.lua文件如下:
1 | |
这个init.lua文件加载了同一文件夹下的其他模块,并将它们放入了一个表中返回。当你在其他地方使用require("mylib")时,你实际上得到的是这个表,它包含对moduleA和moduleB的引用。
init.lua文件在Lua的包结构中起着核心作用,它使得包的使用更加方便和直观。通过使用init.lua,你可以将一个包作为一个单一的单位来加载和管理,而不是单独处理包中的每个模块。
文件组织结构案例
让我们通过一个具体的案例来展示:
- 包、子包、模块和子模块的物理层面组织
- 它们在Lua中如何被
require调用 - 它们在命名空间层面的结果。
假设我们有以下的文件结构:
1 | |
mylib是一个包。moduleA.lua是mylib包的一个模块。subpackage是mylib的一个子包。moduleB.lua是subpackage的一个模块。
使用require加载:
- 要加载
mylib包
可以使用require("mylib")。
这将执行mylib文件夹中的init.lua文件。 - 要加载
mylib中的moduleA模块
可以使用require("mylib.moduleA")。 - 要加载
subpackage中的moduleB模块
可以使用require("mylib.subpackage.moduleB")。
命名空间的结果:
mylib
在命名空间中代表包的顶层。moduleA
成为mylib命名空间的一部分,可以通过mylib.moduleA访问其中的内容(假设moduleA返回了一个表)。subpackage
本身也是一个命名空间,属于mylib的子命名空间。moduleB
在mylib.subpackage命名空间下,可以通过mylib.subpackage.moduleB访问其中的内容(同样假设moduleB返回了一个表)。
练习题
写一个包,里面包含栈,链表,队列,哈希表,树,堆等模块。需要写的标准,有独立运行沙盒,并且通用。
6. 文件IO
Lua的IO操作主要分为两种模式:简单模式和完整模式。
6.1 简单模式
在 Lua 中,简单模式(Simple I/O)是处理文件和标准输入输出的一种方便方式。
它适合于简单的输入输出需求,尤其是小型脚本或命令行程序。
模式特点:
- 不需要显式打开和关闭文件,Lua 自动处理。
- 默认情况下,标准输入和输出分别关联到系统的标准输入(通常是键盘)和标准输出(通常是终端或屏幕)。
使用场景:
- 适用于简单的文本读写操作。
- 当需要快速从控制台输入读取或向控制台输出写入时。
相关方法:
io.input
设置或获取当前输入文件
参数:可选,文件名或文件句柄io.input('example.txt')- io.input():close()
关闭当前输入文件io.input():close()
- io.input():close()
io.output
设置或获取当前输出文件
参数:可选,文件名或文件句柄io.output('output.txt')- io.output():close()
关闭当前输出文件io.output():close()
- io.output():close()
io.write
控制台输出或文件写入数据
参数:需要写入的字符串io.write("Hello, world\n")io.read
控制台输入或文件读取数据local line = io.read("l")
参数:读取模式"a":
从当前位置读取整个文件。"l":
读取下一行。这是默认参数,如果没有指定参数,io.read()将采用这种方式。返回的字符串不包括换行符。"L":
类似于l,但是包括换行符在内的完整行。"n":
读取一个数字并返回它。如果读取失败,返回 nil。- 数字:
读取指定数量的字符。例如,io.read(5)将读取五个字符。
io.lines
以迭代的方式逐行读取文件
参数:文件名称
非常适用于处理大文件或逐行处理文件内容的场景。
每次迭代都读取文件的下一行,直到文件结束。
这种方法的优点是简洁和易于处理大文件,因为它不会一次性将整个文件内容加载到内存中。1
2
3for line in io.lines("example.txt") do
print(line)
endprint
向控制台打印数据
参数:需要打印的值print("Hello, world")
其中print和io.write的区别是:
- 格式化:
print自动在其参数之间添加空格,并在输出的末尾添加换行符。-
io.write则不添加任何额外的字符,完全按照提供的参数输出。
- 参数类型:
print可以接受任何类型的参数,并会调用tostring函数将其转换为字符串。io.write只能接受字符串或数值类型的参数。
- 输出目标:
print默认输出到标准输出,通常是控制台或终端。io.write则输出到当前的输出文件,这可以是通过io.output设置的任何文件,如果没有特别设置,则默认也是标准输出。
应该只在代码的调试部分使用print!
需要正式使用且完全控制输出时,应该使用io.write!
案例:
1 | |
总的来说:io.read与io.write更适用于文件操作,而print更适用于简单的标准输出。
当设置了io.input和io.output后,io.read和io.write将操作指定的文件,而不是控制台的输入输出。
简单模式提供了一种快捷的方式来进行基本的输入输出操作,但在需要更精细控制文件操作时,应考虑使用完整模式(Complete I/O)。
6.2 完整模式
在 Lua 中,完整模式(Complete I/O)提供了对文件输入输出操作的完整控制。
完整模式适合于需要精确控制文件读写操作的场景,特别是处理较大的数据时。它也允许你同时操作多个文件。
与简单模式相比,完整模式允许你打开特定的文件进行读写,并且在操作完成后关闭文件。
6.2.1 基本用法
打开文件:
使用io.open打开文件。
它接受两个参数:文件名,模式。
打开模式如下:"r":以只读方式打开文件。文件必须存在。"w":以写入方式打开文件,用于创建新文件或覆盖现有文件。"a":以追加方式打开文件,写入的数据将添加到文件末尾。如果文件不存在,将创建一个新文件。"r+":以读写方式打开一个现有文件。"w+":以读写方式打开文件,用于创建新文件或覆盖现有文件。"a+":以读写方式打开文件,写入的数据将添加到文件末尾。如果文件不存在,将创建一个新文件。"b":在模式字符串的末尾添加(如"rb"、"wb"或"ab"),用于以二进制模式打开文件。在某些系统中,这与文本模式可能无区别。
本函数有两个返回值:文件句柄和错误信息。
- 如果成功,您将得到一个文件句柄用于后续的读写操作
- 如果失败,文件句柄将为
nil,并且可以获取一个描述错误原因的字符串。
错误处理:
在打开文件时要检查错误。io.open在失败时返回 nil 和错误信息。读取文件:
使用file:read方法进行读取。
它的参数与io.read相似,如"a"(读取全部内容)、"l"(读取一行)等。
例如,file:read("a")读取整个文件。写入文件:
使用file:write方法写入。
你可以传递任意数量的参数,它们会被顺序写入。
例如,file:write("Hello World\n")会写入字符串。文件位置:
可以使用file:seek方法移动文件读写位置。缓冲:
默认情况下,输出是缓冲的。
可以使用io.flush来刷新输出缓冲区。关闭文件:
使用file:close方法关闭文件。这个步骤很重要,以确保所有数据都正确保存并释放文件资源。
案例如下:
1 | |
6.2.2 模式混用与流缓存
函数io.input与io.output允许混合使用简单与完整两种I/O模式。
- 调用无参的
io.input与io.output可以获得当前的输入输出流(无论是什么模式的) - 调用有参的
io.input(流)与io.output(流)可以设置当前的输入输出流(无论是什么模式的)
所以也可以缓存多个流来回调换。
代码如下:
1 | |
6.3 其他文件操作
file:seek([whence[, offset]])**:
**作用:移动文件读写指针到指定位置。
参数:whence:基准位置(”set”,”cur”,”end”)。offset:相对于基准位置的偏移量。案例:
1
2
3
4local file = io.open("example.txt", "r")
file:seek("end", -10) -- 移动到文件末尾前的 10 个字节
print(file:read("*a"))
file:close()io.tmpfile()**:
**作用:创建一个临时文件,用于读写操作。文件在程序结束或关闭时自动删除。
无参数
案例:1
2
3
4
5local tmp = io.tmpfile()
tmp:write("临时数据")
tmp:seek("set")
print(tmp:read("*a")) -- 读取写入的内容
tmp:close() -- 关闭临时文件,文件被自动删除file:flush()**:
**作用:立即将文件的输出缓冲区内容写入磁盘,而不等待自动刷新。
无参数
案例:1
2
3
4local file = io.open("example.txt", "w")
file:write("一些数据")
file:flush() -- 确保数据写入磁盘
file:close()file:setvbuf(mode, size)**:
**作用:设置文件的缓冲模式。
参数:mode:缓冲模式(”no”,”full”,或 “line”)。size:缓冲区大小(可选)。案例:
1
2local file = io.open("example.txt", "w")
file:setvbuf("full", 1024) -- 设置为全缓冲,缓冲区大小 1024 字节os.rename(oldname, newname)**:
**作用:重命名文件或目录。
参数:oldname:原文件或目录名。newname:新文件或目录名。案例:
1
os.rename("oldfile.txt", "newfile.txt")os.remove(filename)**:
**作用:删除指定的文件。
参数:filename:要删除的文件名。
案例:1
os.remove("unnecessaryfile.txt")6.4 其他系统调用
os.exit([code[, close]])**:
**作用:终止程序运行。
参数:code:退出码(可选),默认为零表示成功。close:布尔值,确定是否关闭 Lua 虚拟机。
案例:1
2os.exit() -- 正常退出
os.exit(1) -- 错误退出os.getenv(varname)**:
**作用:获取环境变量的值。
参数:varname:环境变量名。
案例:1
2local path = os.getenv("PATH")
print(path)os.execute(command)**:
**作用:运行一个系统命令。
参数:command:要执行的命令字符串。
案例:1
os.execute("ls -l") -- 在 Unix/Linux 上列出当前目录io.popen(command[, mode])**:
**作用:开启一个进程并连接到其标准输入或输出。
参数:command:要执行的命令。mode:连接类型(”r” 读或 “w” 写)。
案例:1
2
3
4
5local p = io.popen("ls", "r") -- 在 Unix/Linux 上读取目录内容
for line in p:lines() do
print(line)
end
p:close()练习题
编写一个Lua脚本来执行以下任务:
- 读取文件:
从一个名为example.txt的文件中读取内容。 - 内容处理:
对读取的每一行内容执行以下操作:- 将每行的内容转换为大写。
- 在每行的前面添加行号,格式为
Line [行号]:。
例如,第一行应该被修改为Line 1: [内容]。
- 写入处理后的内容:
将处理后的每一行内容写入到一个新的文件processed_output.txt中。 - 复制文件内容:
将example.txt文件的原始内容复制到一个新文件copy_of_example.txt中。
example.txt原文您随便编吧
7. 错误处理
7.1 报错
在Lua中,error函数和assert方法是两种常用的报错机制。
它们用于不同的场景并具有不同的工作原理。
这两个函数都是错误处理的关键部分,它们使您能够在发现问题时立即中断程序的执行,并提供有关问题的信息。它们在Lua编程中非常有用,尤其是在处理不可恢复的错误或无效的输入时。
下面详细解释这两个函数的用法和原理。
7.1.1 error函数
error(message [, level])
参数:
message:错误信息,通常是字符串。level:可选参数,用于确定错误信息中提供的堆栈跟踪的级别。
是一个整数,用于确定错误信息中提供的堆栈跟踪的起始点。
这个数字决定了栈回溯从哪一层函数调用开始。- 级别 1 表示在 error 被调用的地方(默认级别)
- 级别 2 表示在调用 error 函数的函数中,依此类推。
返回值:
当调用error函数时,程序不会继续到error调用之后的代码。
因此,error函数本身并不返回任何值。
原理:
error函数抛出一个Lua错误,终止当前函数的执行。- 错误被抛出后,Lua会尝试查找最近的错误处理函数
(通常是pcall或xpcall中定义的,后续会在错误处理中介绍)。 - 如果没有找到错误处理函数,程序将终止,并显示错误信息。
使用场景:
- 当您的代码在某些条件下需要主动抛出错误时,使用
error。 - 通常用于检测和报告函数的非法参数或其他不期望的情况。
案例:
1 | |
7.1.2 assert函数
assert(v [, message])
参数:
v:要检测的表达式或值。message:可选参数,如果v为假,则显示的错误信息。
返回值:
- 如果条件为真,
assert函数返回所有传入的参数。 - 如果条件为假,则
assert会调用error,抛出一个错误。不会有返回值。
原理:
assert函数首先检查第一个参数v是否为真(即非nil且非false)。- 如果
v为真,assert返回所有传入的参数。 - 如果
v为假,assert使用error函数抛出错误,错误信息为第二个参数message,如果未提供message,则有一个默认错误信息。
- 如果
- 类似于
error,如果错误未被捕获,程序将终止。
使用场景:
- 用于条件检查,确保程序运行期间的某个条件为真。
- 常用于参数检查或在重要条件不满足时快速失败。
案例:
1 | |
二者区别:
error:
- 直接抛出一个错误。
- 可以自定义错误信息,并且可以选择性地指定堆栈跟踪的级别。
- 这通常用于表示一种异常情况,如程序内部逻辑错误,或者当代码达到一个不应该到达的状态时。
- 它更关注于代码内部的异常状态。
assert:
- 用于断言一个条件为真。如果条件为假,则抛出错误。
- 通常只需要一个错误消息。
- 这通常用于验证函数的输入参数或确保程序运行期间某些条件得到满足。
- 它更多用于输入验证和预期条件的检查。
7.2 错误处理
在Lua中,错误处理和异常处理主要通过pcall和xpcall两个函数实现。
这些函数提供了一种处理运行时错误的方式,允许程序捕获和处理异常,而不是直接崩溃。
下面详细解释这两个函数。
7.2.1 pcall(Protected Call)
pcall(function, arg1, arg2, ...)
参数:
- 要调用的函数
- 该函数的参数(数量可变)
返回值:
布尔值
无错误:返回true
有错误:返回false
后续返回值
无错误:被调函数的所有返回值
有错误:错误信息(是一个对象)
原理:pcall会以一种保护模式执行一个函数(参数1),并在执行过程中捕获发生的任何错误。
这意味着如果被调用的函数中发生了错误(例如,通过error函数抛出),pcall可以防止错误导致整个程序崩溃。
类似于其他语言的try catch,但pacll只try了并返回结果告诉你有没有错,并没有catch。
适用场景:
当你想安全地调用一个可能会出错的函数时使用pcall,尤其是在错误可能导致程序中断的情况下。
案例:
1 | |
7.2.2 xpcall(eXtended Protected Call)
xpcall(function, errorHandler, arg1, arg2, ...)
参数:
- 被调用的函数
- 一个错误处理函数
- 被调用函数的参数(数量可变)
返回值:
- 布尔值
与pcall一样。- 没错误:返回
true; - 有错误:返回
false。
- 没错误:返回
- 后续返回值
- 没错误:返回被调用函数的所有返回值。
- 有错误:返回错误处理函数的返回值。
原理:xpcall与pcall类似,但它允许你指定一个错误处理函数,这个函数会在发生错误时调用。
完全类似于其他语言的try catch。被调用函数就是try的内容,错误处理函数就是catch的内容。
适用场景:
当你需要更详细的错误信息或自定义错误处理逻辑时,使用xpcall。
错误处理函数可以用于记录错误、清理资源或以其他方式响应错误。
案例:
1 | |
7.3 自定义错误信息与栈回溯
在Lua中,错误信息和栈回溯(stack traceback)是调试和错误处理的关键组成部分。当Lua代码发生错误时,理解错误信息和如何获取栈回溯信息对于快速定位和解决问题至关重要。
错误信息:
在Lua中,当代码运行出错时,Lua运行时会生成一个错误信息的对象。
错误信息通常包含错误的描述,有时还包括发生错误的位置信息。
可以使用error或assert函数可以生成自定义错误信息。
把自定义的错误信息当做参数传给这俩函数就可以。
错误信息通常是字符串,描述了发生的错误。
也可以是任何类型的值(如表、数字等)。不过在实际应用中,使用字符串作为错误对象更为常见,因为它们能提供易于理解的错误描述。
栈回溯:
在错误信息中可以增加栈回溯。
栈回溯提供了错误发生时的函数调用序列,帮助开发者理解错误发生的上下文。它特别有用于定位错误发生的位置和原因。
可以使用xpcall函数和debug库中的函数来进行栈回溯信息的报错。
案例如下:
1 | |
在这个例子中,如果riskyFunction发生错误,xpcall会调用myErrorHandler,后者生成包含错误信息和栈回溯的字符串。这样可以更容易地定位和理解错误的原因。
7.4 调试库函数
Lua的调试库提供了一系列功能强大的工具,用于调试和检查Lua代码的运行时状态。
调试库的常用函数有:
debug.debug
参数:无参数无返回值
作用:该函数提供了一个简单的交互式调试环境。
当调用这个函数时,Lua会暂停执行当前程序,并提供一个命令行界面,允许你检查和修改变量,甚至可以调用函数。直到你输入一个空行,这时Lua会退出调试环境并继续执行原来的程序。debug.traceback
参数:message(可选):
一个初始错误消息。如果提供,它将被附加在栈回溯信息的开头。level(可选):
一个数字,用于指定从哪一层调用栈开始生成栈回溯信息。
默认值是1,表示当前函数的调用者。
返回值:返回一个字符串,包含了从指定的栈层开始到栈底的所有函数调用信息。
作用:该函数用于生成当前线程的栈回溯。
它提供了从当前函数到栈底的所有函数调用信息,这对于理解程序在某一时刻的执行流程非常有用。debug.getinfo
参数:function或level:指定要查询的函数或堆栈层级。what(可选):一个字符串,指定要返回的信息类别。"n": 返回函数名。"S": 返回函数定义的源文件名。"l": 返回函数定义的行号。"u": 返回函数的上值(upvalue)数量。"f": 返回函数本身。"L": 返回函数活动的行号表。">": 仅对 C 函数有效,不返回函数的源文件名和行号信息。
返回值:一个包含了所请求信息的表。
功能:获取关于一个特定函数的信息。用于检查函数的详细信息,包括源文件、定义的行号、是否是Lua函数等。debug.getlocal
参数:level:堆栈层级。local:局部变量的索引。
返回值:变量的名称和值。
功能:获取一个函数的局部变量的名称和值。
可以用来检查特定函数调用中的局部变量。debug.setlocal
参数:与debug.getlocal相同。
返回值:被设置的变量的名称,如果无法设置则为nil。
功能:设置一个函数的局部变量的值。debug.getupvalue和debug.setupvalue
参数:func:函数。up:上值的索引。
返回值:
getupvalue返回上值的名称和值,setupvalue返回被设置的上值的名称。
功能:getupvalue用于获取一个闭包的上值(upvalue),setupvalue用于设置这些值。debug.getmetatable和debug.setmetatable
参数:object(要获取或设置元表的对象)。
返回值:getmetatable返回元表,setmetatable返回对象。
功能:getmetatable用于获取一个对象的元表,setmetatable用于设置对象的元表。debug.getregistry
返回值:Lua注册表。
功能:获取Lua的注册表。
注册表是一个全局表,用来保存所有用C注册到Lua的对象。debug.getuservalue和debug.setuservalue
参数:用户数据对象。
返回值:getuservalue返回附加值,setuservalue返回用户数据对象。
功能:用于获取或设置用户数据(userdata)的附加值。
注意:
debug库的使用可能会降低代码的可移植性和性能它更多用于开发和调试阶段,而不是生产环境!
练习题
创建一个Lua脚本,执行以下任务:
- 定义函数:
编写一个函数safeDivision(numerator, denominator),该函数接受两个参数:分子numerator和分母denominator。 - 错误检查:
- 如果分母为零,则使用
error函数抛出错误。 - 使用
assert来断言结果不是无限大。
- 如果分母为零,则使用
- 错误处理:
- 使用
xpcall调用safeDivision,并在调用中故意传递一个零作为分母来触发错误。 - 为
xpcall提供一个自定义错误处理函数,该函数生成并返回包含错误信息和栈回溯的字符串。
- 使用
- 调试信息:
在safeDivision函数内,使用debug.getinfo报告函数被调用时的当前行号和所在的文件。 - 变量探查:
在safeDivision内部,使用debug.getlocal获取并打印所有局部变量的名称和值。
8. 协同程序
协程并不是Lua独有的概念,其他很多语言也都支持协程(C#,Java等)。所以关于协程的概念和定义我们在这里不过多赘述,可以找别的资料去学习。
Lua中的协程是一种非常强大的特性,它允许你编写出非阻塞、协作式多任务的代码。
在Lua中,协程是通过coroutine库来实现的。所有相关的函数都被放在表coroutine中。
应用场景:
- 非阻塞IO操作:
在需要执行长时间运行的IO操作时,例如文件读写或网络操作,协程允许这些操作在不阻塞整个程序的情况下执行。 - 游戏开发:
在游戏编程中,协程可以用来编写复杂的游戏逻辑,如角色行为或动画,而不影响游戏的主循环。 - 协作式多任务:
当需要多个任务交替执行时,协程提供了一种实现方式,每个任务可以主动挂起和恢复,避免了传统并发编程中的复杂性。 - 复杂流程控制:
在需要管理复杂的工作流程时,协程可以使得逻辑控制更加清晰。
8.1 创建协程
在Lua中,可以通过以下两种方式创建协程:
使用
coroutine.create
功能:创建一个新的协程,但不立即启动它。
参数:接受一个Lua函数。
返回值:返回一个协程对象(thread)。
示例:1
2
3
4
5co = coroutine.create(
function()
print("Hello, Coroutine!")
end
)使用
coroutine.wrap
功能:
同样创建一个新的协程,但返回一个函数而不是协程对象。
当调用这个函数时,传入的参数会作为协程的参数,并且协程会被启动或恢复执行。
参数:接受一个Lua函数。
返回值:返回一个函数,用于启动或恢复协程。
示例:1
2
3
4
5
6co = coroutine.wrap(
function()
print("Hello, Coroutine!")
end
)
co() -- 启动协程
二者区别:
- 返回类型:
coroutine.create返回一个协程对象-
coroutine.wrap返回一个函数。
- 错误处理:
coroutine.create需要配合coroutine.resume使用,可以显式处理错误。-
coroutine.wrap在内部处理了错误,如果协程内部发生错误,它会抛出错误。
- 使用便利性:
coroutine.wrap提供了一种更为简洁的协程使用方式,不需要显式调用coroutine.resume。
注意:
虽然warp比create简化了操作,但也降低了灵活性。
通过warp创建的协程无法进行状态检查与异常处理。
8.2 协程控制
协程一旦创建,可以通过以下函数来控制其执行:
coroutine.resume
功能:用于启动或继续一个协程的执行。
会切换到指定的协程上下文,开始或继续执行该协程的代码。
如果协程之前被yield挂起,则从yield的位置继续执行。
参数:- 目标协程对象:
第一个参数是一个由coroutine.create创建的协程。 - 传递给协程的参数:
在启动协程时,这些参数将被传递给协程的主体函数。
返回值:
第一个返回值:布尔值
表示协程是否成功切换(true表示成功,false表示有错误发生)。后续返回值:
- 如果协程内部执行了
yield,则这些返回值是yield传递出来的。 - 如果协程运行到结束,则是协程函数的返回值。
- 如果发生错误,则返回错误信息
- 如果协程内部执行了
(与之前错误处理部分的pcall相同,resume也是运行在保护模式中的)
案例:
1
2
3
4
5
6
7
8
9co = coroutine.create(
function(a, b)
print("co", a, b)
local r = coroutine.yield(a + b, a - b)
print("co", r)
return a * b
end
)
coroutine.resume(co, 20, 10) -- 启动协程- 目标协程对象:
coroutine.yield
功能:
用于挂起(暂停)当前协程的执行,并将控制权交还给coroutine.resume的调用者
参数:
可变参数:这些参数将被传递给resume的调用者。
返回值:
由下一次coroutine.resume调用提供的参数决定。
案例:1
2
3
4
5
6
7
8
9
10co = coroutine.create(
function(x)
for i = 1, x do
print("co", i)
coroutine.yield()
end
end
)
coroutine.resume(co, 3) -- 第一次执行
coroutine.resume(co) -- 第二次执行,继续从yield处执行在这个案例中,协程每次通过
yield挂起,然后由外部的resume调用继续执行。
这种方式可以用于控制协程的执行节奏,或者在等待某个事件时暂停协程。
协程是支持嵌套的。
可以由一个协程去调用另一个协程,那么另一个协程就是这个协程的子协程。
resume-yield数据交换
你应该有留意到resume函数与yield函数的参数与返回值是存在一定程度的相互关联的。
实际上我们可以利用这一点做到协程内外的数据交换。
它的原理是这样的:
当调用
resume函数用于启动协程时,
会把额外参数传递给协程目标函数的参数表。
例如:1
2
3
4
5
6co = coroutine.create(
function(a, b, c)
print("co", a, b, c+2)
end
)
coroutine.resume(co, 1, 2, 3) --> co 1 2 5当调用
resume函数用于恢复协程时,
会把额外参数传递给yield函数的返回值
例如:1
2
3
4
5
6
7
8co = coroutine.create(
function(x)
print("co1", x)
print("co2", coroutine.yield())
end
)
coroutine.resume(co, "hi") --> co1 hi
coroutine.resume(co, 4, 5) --> co 45当协程遇到
yield会暂停协程,回到最开始调用协程的地方(也就是resume)
会把yield的参数传递给resume的第二个返回值(没有遇到错误的情况下)
例如:1
2
3
4
5
6co = coroutine.create(
function(a, b)
coroutine.yield(a + b, a - b)
end
)
print(coroutine.resume(co, 20, 10)) --> true 30 10当协程运行结束时(遇到
return或代码段运行完了),
会把协程return的值传递给resume的第二个返回值(没有遇到错误的情况下)
例如:1
2
3
4
5
6co = coroutine.create(
function()
return 6,7
end
)
print(coroutine.resume(co)) --> true 6 78.3 协程状态
8.3.1 状态与状态转换
在Lua中,协程有四种主要的状态:挂起(suspended)、运行(running)、正常(normal)和死亡(dead)。理解这些状态及其转化过程对于有效地使用协程至关重要。
- 挂起(Suspended)
这是协程最常见的状态。
一个协程在两种情况下处于挂起状态:- 当它尚未开始运行时。
- 当它通过
coroutine.yield暂停执行时
- 运行(Running)
当协程正在执行时,它处于运行状态。
在任何时刻,只有一个协程处于运行状态,即当前正在执行的协程。 - 正常(Normal)
一个协程在调用其他协程(即在外部协程的coroutine.resume调用中)被视为处于正常状态。这个状态通常表示协程处于活动状态,但当前并未执行代码。 - 死亡(Dead)
当协程的主体函数结束执行后,协程进入死亡状态。
一个协程也会因为运行时错误而死亡。
8.3.2 状态查询
我们可以通过两个函数来对协程进行状态查询:
coroutine.status
功能:获取一个协程的当前状态。
参数:一个协程对象(通过coroutine.create创建的)。
返回值:一个字符串,表示协程的状态。
示例:1
2
3
4
5
6
7
8
9
10
11
12co = coroutine.create(
function()
print("Inside Coroutine")
coroutine.yield()
print("Resuming Coroutine")
end
)
print("Status:", coroutine.status(co)) -- "Status: suspended"
coroutine.resume(co)
print("Status:", coroutine.status(co)) -- "Status: suspended"
coroutine.resume(co)
print("Status:", coroutine.status(co)) -- "Status: dead"coroutine.running()
功能:获取当前正在运行的协程及一个布尔值,表示是否为主协程。
参数:无参数。
返回值:当前正在运行的协程对象和一个布尔值。- 如果当前正在运行的协程是主协程(即Lua主线程)
则返回的布尔值为true;否则为false。 - 如果没有协程在运行,则返回
nil。
示例:
1
2
3
4
5
6
7function printCoroutineStatus()
local co, ismain = coroutine.running()
print("Running Coroutine:", co, "Is Main Coroutine:", ismain)
end
printCoroutineStatus() -- 在主协程中调用
co = coroutine.create(printCoroutineStatus)
coroutine.resume(co) -- 在子协程中调用练习题
- 如果当前正在运行的协程是主协程(即Lua主线程)
题目 1:协程状态监控
创建一个协程,并在外部循环中监控并打印其状态。需要涉及到协程的全部状态。
题目 2:计时器
实现一个协程,能在指定时间后执行某个指定的函数。
该计时器可以暂停,恢复,重置,取消,循环等操作。
9. 反射
反射是程序用来检查和修改自身某些部分的能力。
Lua 不具备传统编程语言中的完整反射机制,但它也支持几种不同的反射机制:
type和pairs这样的允许运行时检查和遍历未知数据结构的函数load和require这样运行程序在自身中追加代码或更新代码的函数
不过仍有一些方面是缺失的,就需要调试库(debug library)来弥补这方面的空白。
其它几个前面的章节都已经介绍过了,本章节主要介绍动态加载代码的几个函数与调试库的反射功能。
9.1 动态加载代码
lua可以实现动态加载代码主要是靠以下几个函数:
- require:
模块化和依赖管理,带有缓存。
(实际上require是对loadfile的封装) - load:
从字符串动态编译代码,提供运行前的控制和错误处理。 - loadfile:
从文件动态编译代码,类似于load但用于文件。 - dofile:
直接执行文件中的代码,用于快速脚本执行。
其中require已经在前面的5.2.2加载模块部分讲解过了,我们这里只对剩下的三个函数进行讲解。
9.1.1 load
Lua 的 load 函数是一个强大的工具,用于动态加载和执行字符串形式的 Lua 代码。
功能
- 动态执行代码:
load函数用于编译一个字符串为 Lua 代码块(函数),但不立即执行它。
这允许您在运行时动态地加载和执行代码。 - 安全性:
与直接使用loadstring或dofile相比,load提供了更高的安全性,因为它允许您检查代码是否正确编译,然后再执行。
参数:
- 字符串或加载器函数:
load的第一个参数可以是包含 Lua 代码的字符串,或者是一个加载器函数。
加载器函数在每次调用时应返回代码的新片段,直到没有更多的片段时返回nil。 - 块名称(可选):
用于错误信息和调试信息中的代码块名称。 - 模式(可选):
控制是否允许加载二进制代码块。"b"(只允许二进制代码块)"t"(只允许文本代码块)-
"bt"(两者都允许)
- 环境(可选,在 Lua 5.2 及更高版本中):
指定代码块将在其中运行的环境。详见前面5.1.2局部环境提到的内容
返回值:
- 如果编译成功,返回编译后的代码块(函数);
- 如果编译失败,返回
nil与错误信息
适用场景:
- 配置文件:
动态加载和执行配置文件,特别是当配置文件格式为 Lua 代码时。 - 动态代码执行:
在需要根据条件构造并执行代码时,例如在模板引擎或某些类型的 DSL 中。 - 沙盒执行:
在自定义环境中安全地执行第三方代码,可以用于插件系统或脚本沙盒。
注意事项:
- 安全风险:
执行用户提供的代码时需谨慎,因为它可能导致安全漏洞,如代码注入攻击。 - 性能考虑:
频繁地编译和执行大量代码可能会影响性能。 - 环境隔离:
在 Lua 5.2 及更高版本中,可以通过设置环境参数来限制代码块的执行环境,减少安全风险。
示例:
1 | |
这个例子展示了如何使用 load 编译和执行一个简单的数学运算。
如果字符串有效,编译后的函数会被调用并输出结果。
如果字符串包含错误,将打印出错误信息。
游戏开发中的用法:
在实际的游戏开发中,Lua的load函数可以用于多种场景,尤其是在那些需要动态脚本执行或灵活配置的场合。
以下是一些典型的应用例子:
- 动态配置和脚本
load可以用来执行游戏的配置脚本。
这些脚本可能包含关于游戏级别、角色属性或游戏规则的信息。通过动态加载这些脚本,可以在不重启游戏的情况下修改配置。 - 热更新和模块化
在游戏运行时动态更新代码是一种常见需求。
使用load,开发者可以实现热更新机制,允许游戏在运行时加载和执行新的或修改过的脚本,从而快速迭代和修复bug。 - 插件和扩展系统
游戏可以提供一种机制,允许第三方开发者或玩家编写自己的脚本来扩展游戏功能。
通过load函数,可以安全地加载并执行这些插件或扩展脚本。 - 条件式逻辑执行
在某些情况下,游戏的特定行为可能需要根据运行时的条件动态确定。load可以用来编译和执行构建在运行时的脚本片段,实现复杂的、条件性的逻辑。 - 脚本化的AI和事件处理
在复杂的游戏中,AI行为或事件响应逻辑可能非常复杂。load可以用于执行动态生成的脚本,这些脚本定义了角色的行为或游戏中的事件响应。
注意事项:
- 安全性:
动态执行代码增加了出错的风险,特别是当执行用户提供的脚本时。
需要确保脚本执行环境的安全性,防止恶意代码执行。 - 性能:
频繁编译和执行大量的脚本可能会影响游戏性能,特别是在资源有限的设备上。
总之,load在游戏开发中提供了极大的灵活性,但也带来了安全和性能上的挑战。正确使用时,它可以极大地增强游戏的动态性和可扩展性。
9.1.2 loadfile
功能:loadfile 用于读取 Lua 文件的内容并编译为函数,但不立即执行它。
参数:
文件路径:
指定要加载的 Lua 文件的路径。
如果没有提供路径,则默认尝试加载当前工作目录下的文件。
返回值:
- 成功:返回编译后的函数。
- 失败:返回
nil和一个错误消息。
适用场景:
- 配置文件加载:动态加载配置文件,尤其是内容可能更改的情况。
- 模块和脚本加载:作为模块系统的一部分,用于加载模块代码。
- 条件执行:在确定是否执行代码之前,先对文件进行语法检查。
注意事项:
- 文件路径:确保文件路径正确,且文件具有正确的语法。
- 错误处理:由于
loadfile不会立即执行代码,需要处理编译过程中可能出现的错误。
原理:loadfile 函数首先将文件内容读入内存,然后编译这些内容为 Lua 函数(字节码)。这个函数可以被稍后调用以执行文件中的代码。
案例:
假设你有一个配置文件 config.lua,其中包含一些游戏设置:
1 | |
你可以使用 loadfile 来加载这个配置文件,然后根据需要执行它:
1 | |
在这个示例中,loadfile 用于读取并编译 config.lua 文件,但不立即执行它。
这允许进行错误检查或其他逻辑判断,然后再通过调用返回的函数来实际应用配置。
9.1.3 dofile
功能:dofile 用于读取并立即执行 Lua 文件。
参数:
文件路径:指定要执行的 Lua 文件的路径。
返回值:
文件中最后一个表达式的返回值。
适用场景:
- 直接执行脚本:当需要立即执行一个 Lua 脚本文件时,特别是初始化脚本或配置。
- 简化的文件执行:对于不需要预先检查或多次执行的脚本。
注意事项:
- 错误处理:
dofile在执行时可能抛出错误,需要相应地处理这些错误。 - 性能考虑:对于频繁执行的代码,
dofile可能不如预编译的函数高效。
原理:dofile 函数读取文件内容,将其编译为函数,并立即执行这个函数。
案例:
假设你有一个 Lua 脚本 initialize.lua,用于初始化一些游戏数据:
1 | |
你可以使用 dofile 来直接执行这个脚本:
1 | |
在这个示例中,dofile 直接读取并执行了 initialize.lua 文件。这是一种快速方便的方式来执行不需要预编译或特殊错误处理的脚本,例如初始化脚本或简单配置文件。
练习题
题目 1:动态执行代码
描述: 编写一个 Lua 程序,使用 load 函数动态执行给定的数学表达式字符串,并打印结果。例如,给定字符串 "return 2 + 2"。
**预计输出:**4
题目 2:动态修改配置
描述: 假设有一个配置文件 config.lua,内容如上所述。编写一个 Lua 程序,使用 loadfile 函数加载 config.lua 文件,然后动态修改 setting 表中的 volume 和 resolution,最后打印出修改后的配置。
config.lua文件
1 | |
预期输出:
1 | |
9.2 调试库
以下内容更多是用于调试代码或模拟沙盒时使用,而且一边情况下用IDE的断点调试工具更有性价比,可以仅作了解或略过不看
调试库由两类函数组成:
- 自省函数(introspective function)
用来检查一个正在运行的程序的几个方面,如活动函数的栈,正在执行的代码行,局部变量的名称和值。 - 钩子(hook)
用来跟踪一个程序执行的生命周期。
值得注意的是:调试库必须被慎重的使用。
- 调试库的功能普遍性能不高
- 调试库会打破语言的一些固有规则,会导致代码混乱,更难维护
9.2.1 自省函数
Lua的自省(Introspection)功能,主要由debug库提供,使得程序能够在运行时检查其自身的状态和结构。自省功能对于深入理解程序行为、调试和高级编程任务非常重要。
以下是Lua中一些主要的自省函数及其功能:
- debug.getinfo
功能:返回有关函数的详细信息。
参数:接受一个函数或堆栈层级(数字)。
返回值:一个包含函数信息的表,如函数名、定义的源文件、行号等。 - debug.getlocal和debug.setlocal
功能:分别用于获取和设置一个函数的局部变量的名称和值。
参数:堆栈层级和局部变量的索引。set时还需传入新的值。
返回值:
获取时返回局部变量的名称和值。
设置时返回被设置的变量的名称,如果设置失败,则为nil。 - debug.getupvalue 和 debug.setupvalue
功能:分别用于获取和设置一个函数的上值(upvalue,闭包中的外部变量)。
参数:函数和上值的索引。
返回值:getupvalue返回上值的名称和值,setupvalue返回被设置的上值的名称。 - debug.getmetatable 和 debug.setmetatable
功能:分别用于获取和设置一个对象的元表(metatable)。
参数:对象(表或其他可设置元表的类型)。
返回值:元表。 - debug.traceback
功能:生成当前调用栈的回溯信息。
参数:可选的消息字符串和起始堆栈层级。
返回值:包含回溯信息的字符串。 - debug.getregistry
功能:获取Lua的注册表,这是一个特殊的表,用于存储所有用C注册到Lua的对象。
返回值:Lua注册表。
我们接下来挑几个重点进行介绍
getinfo
debug.getinfo 是 Lua 中的一个强大的自省函数,用于获取有关函数的详细信息。
参数:
函数或堆栈层级:
可以是一个函数或表示调用堆栈层级的数字。传递函数时,获取该函数的信息;
传递数字时,获取堆栈上相应层级的函数的信息。
‘what’ 字符串(可选):
用于指定要返回哪些信息。
可能的值包括"n"(名称)name,namewhat"S"(源)source,short_src,what,linedefined,lastlinedefined"l"(行号)currentline"u"(上值数量)nup,nparams,isvararg"f"(函数本身)func"L"(行号列表)activelines
返回值:
是一个表,可能包含以下字段(由传入的what字符串决定有那些字段):
- source:函数定义的源文件或代码块。
- short_src:源文件或代码块的简短版本,通常用于错误消息。
- linedefined:函数定义的开始行号。
- lastlinedefined:函数定义的结束行号。
- what:函数的类型(”Lua”、”C” 或 “main”)。
- name:函数的名称(如果可用)。
- namewhat:描述名称的类型(如 “global”、”local”、”method” 等)。
- nups:函数上值的数量。
- nparams(仅在 Lua 5.1 中不可用):函数参数的数量。
- isvararg(仅在 Lua 5.1 中不可用):函数是否是可变参数函数。
- func:函数本身。
- activelines:包含所有活跃行号的表。
使用场景:
- 调试和错误报告:获取函数的详细信息,用于调试或生成错误报告。
- 性能分析:分析函数调用和执行,如在性能分析工具中。
- 高级函数操作:在需要详细了解函数行为的高级编程任务中。
代码案例:
获取一个函数的信息并打印出来:
1 | |
在这个例子中,我们定义了一个简单的函数 testFunction,然后使用 debug.getinfo 获取它的信息,并遍历这些信息将它们打印出来。
注意事项:
debug.getinfo通常用于调试目的,因为它可能会影响性能。- 函数的某些信息(如名称)可能不总是可用,特别是对于匿名函数或在某些上下文中调用的函数。
- 在安全性敏感的环境中慎用,因为它可以用来探查函数的内部细节。
getlocal,setlocal
getlocal
debug.getlocal 是 Lua 中用于获取函数局部变量信息的自省函数。
它允许你查看或修改函数的局部变量,这在调试和高级编程中非常有用。
参数:
- 函数调用堆栈层级:
一个数字,指定要访问的堆栈层级。1表示当前函数,2表示调用当前函数的函数,依此类推。 - 局部变量的索引:
一个数字,表示要访问的局部变量的索引。
局部变量按照它们在代码中出现的顺序进行索引。
返回值:变量名称和值
- 如果成功,返回局部变量的名称和值;
- 如果索引超出了局部变量的数量,返回
nil。
使用场景:
- 调试:在调试时检查和修改函数的局部变量。
- 运行时分析:分析函数行为,如检查变量的值或状态。
- 高级函数操作:在复杂的编程任务中,如动态修改函数行为。
注意事项:
- 性能影响:
频繁使用debug.getlocal可能会影响性能,特别是在循环或性能敏感的代码中。 - 变量索引:
局部变量的索引可能会因为函数的不同部分而变化,尤其是在存在条件分支或循环时。 - 安全性:
修改局部变量的值可能会导致程序行为不稳定或不可预测,应谨慎使用。
setlocal
debug.setlocal 允许你修改指定函数堆栈层级上的局部变量的值。
参数:
- 堆栈层级:
一个数字,表示要修改的函数在调用堆栈中的层级。
层级1是当前函数,层级2是调用当前函数的函数,依此类推。 - 局部变量的索引:一个数字,表示要修改的局部变量在其函数内的索引。
- 新的值:要设置的新值。
返回值:
- 如果设置成功,返回变量的名称;
- 如果索引超出了局部变量的数量,返回
nil。
使用场景:
- 调试时修改状态:
在调试过程中,可以用来修改函数的内部状态,从而观察不同状态下的行为。 - 运行时行为修改:
在高级编程任务中,动态修改程序的行为,尤其是在测试或特定条件下。
代码案例:
下面是一个简单的示例,演示了如何使用 debug.setlocal 修改函数的局部变量:
1 | |
在这个例子中,testFunction 定义了一个局部变量 a。
我们在 modifyLocalVar 函数中使用 debug.setlocal 来修改 a 的值。
这个例子展示了基本的用法,但请注意,实际中通常需要在函数执行的上下文中使用 debug.setlocal,例如在调试器中或在错误处理函数里。
注意事项:
- 性能和安全:
频繁使用debug.setlocal可能会影响性能,并且不当使用可能导致程序行为不稳定。 - 变量索引:
确定正确的局部变量索引可能有些复杂,尤其是在函数具有复杂的控制流程时。 - 适用场合:通常仅在调试和特定的高级编程场景中使用。
debug.setlocal 提供了强大的能力来动态改变函数的内部状态,但应谨慎使用,以避免不可预期的副作用。
debug.getupvalue 和 debug.setupvalue 是 Lua 中用于访问和修改函数闭包中的上值(upvalues)的函数。在 Lua 的函数编程模型中,闭包和上值是实现函数作用域和持久状态的关键机制。以下是这两个函数的详细描述:
getupvalue,setupvalue
debug.getupvalue
debug.getupvalue 用于获取闭包中的上值(即函数外部的局部变量,被闭包所捕获)。
参数:
- 函数:闭包函数。
- 上值的索引:一个数字,表示要访问的上值的索引。
返回值:
- 如果成功,返回:
- 上值的名称
- 上值的值
- bool 值
isenv上值是否是函数的环境(_ENV)(lua5.2以上版本)
- 如果索引超出了上值的数量,返回
nil。
其中参数isenv避免了一个诡异的问题。
该参数用于说明我们是否处于一个从_ENV变量中查询全局名称的递归调用中。一个不使用全局变量的函数可能没有上值_ENV。
在这种情况下,如果我们试图把_ENV当作全局变量来查询,那么由于我们需要ENV来得到其自身的值,就有可能会陷人无限递归循环。
因此,当isenv为真且函数getvarvalue找不到局部变量或值时,getvarvalue就不应该再尝试全局变量。
使用场景:
- 调试:在调试时检查闭包中捕获的变量。
- 运行时分析:分析闭包行为,特别是在高级编程和动态代码修改中。
代码案例:
获取并打印一个闭包中的上值:
1 | |
在这个例子中,outer 函数创建了一个闭包,该闭包捕获了局部变量 a。我们使用 debug.getupvalue 来获取并打印这个上值的名称和值。
debug.setupvalue
debug.setupvalue 用于设置闭包中的上值。
参数:
- 函数:闭包函数。
- 上值的索引:一个数字,表示要修改的上值的索引。
- 新的值:要设置的新值。
返回值:
- 如果成功,返回:
- 上值的名称
- 上值的值
- bool 值
isenv上值是否是函数的环境(_ENV)(lua5.2以上版本)
- 如果索引超出了上值的数量,返回
nil。
使用场景:
- 运行时行为修改:在高级编程任务中,动态修改闭包捕获的变量。
- 调试和测试:在调试或测试时修改闭包的状态。
代码案例:
修改一个闭包中的上值:
1 | |
在这个例子中,outer 函数返回了一个闭包和一个用于修改闭包上值的函数。我们首先打印了原始的上值,然后使用 debug.setupvalue 修改它,并再次打印以观察变化。
注意事项:
- 性能和安全:频繁使用这些函数可能会影响性能,并且不当使用可能导致程序行为不稳定。
- 适用场合:主要用于调试和特定的高级编程场景。
- 谨慎修改:修改上值可能会对闭包的行为产生重大影响,应谨慎使用。
9.2.2 钩子
Lua 中的钩子(Hook)机制是一个强大的特性,它允许你监视和调试 Lua 程序的行为。通过钩子,你可以追踪程序的执行,比如函数的调用、返回,以及某些特定事件的发生。这在调试和性能分析中非常有用。
钩子函数可以在以下几种事件发生时被调用:
- **”call”**:
当 Lua 调用一个函数时。 - **”return”**:
当 Lua 从一个函数返回时。 - **”line”**:
当 Lua 执行到新的一行代码时。 - **”count”**:
每执行一定数量的指令后。 - **”tail call”**:
执行尾调用时。
尾调用在 Lua 中被视为返回,因此不会触发常规的“call”和“return”事件。
使用钩子:
使用 debug.sethook 函数设置钩子。
这个函数接受三个参数:
- 钩子函数:当指定的事件发生时被调用的函数。
- 字符串:指定触发钩子函数的事件类型。
- 数字(可选):对于 “count” 事件,这个数字表示多少指令执行一次钩子函数。
钩子函数的参数:
钩子函数接受两个参数:
- 事件类型:
一个字符串,表示触发钩子的事件类型(”call”, “return”, “line”, “count”, “tail call”)。 - 行号(仅当事件类型为 “line” 时):表示当前执行的行号。
使用场景:
- 调试:跟踪函数调用和返回,监控程序执行流程。
- 性能分析:通过计数或行号事件监控程序的性能。
- 行为监控:在某些操作发生时进行日志记录或执行特定的代码。
案例:
下面是一个简单的示例,展示如何使用钩子来追踪函数调用:
1 | |
在这个例子中,我们定义了一个名为 trace 的钩子函数,用于在每次 Lua 执行到新的一行代码时打印文件名和行号。
然后我们使用 debug.sethook 设置这个函数为钩子,并指定 “line” 事件触发钩子。
注意事项:
- 性能影响:
频繁触发的钩子(尤其是 “line” 和 “count” 事件)可能会对程序性能产生显著影响。 - 调试与日常使用:
钩子通常用于调试或性能分析,而不是程序的日常功能。 - 安全性:
在钩子函数中执行复杂的操作或修改程序状态需要谨慎,以避免引入错误或不稳定行为。
练习题
题目 1:追踪函数调用
使用 Lua 的调试库,编写一个程序来追踪任意一个函数的调用。程序应该在函数被调用时打印出函数名和调用的参数。
题目 2:实现一个简单的调试器
实现一个简单的 Lua 调试器,它能够在每次执行新的一行代码时打印出当前的文件名和行号。使用 debug.sethook 设置钩子,并实现相应的钩子函数。
题目 3:修改闭包上值
给定以下 Lua 函数:
1 | |
编写一个 Lua 程序,使用 debug.getupvalue 和 debug.setupvalue 函数找到闭包 myClosure 中的上值 secretNumber 并修改它的值。然后验证修改是否成功。
10. 序列化与反序列化
Lua 中的序列化是将表(Lua 的一种数据结构)转换为可存储或传输的格式:
- 字符流(字符串)
- 字节流(二进制)
而反序列化则是将这种格式恢复为原始表的过程。
这在数据持久化、网络通信等方面非常有用。
10.1 字符流
Lua 的序列化与许多其他语言中的序列化机制有所不同。
在诸如 Java、C#、Python 等语言中,序列化通常涉及将数据结构转换为标准化的格式,如 JSON、XML 或自定义的二进制格式。这些格式通常是语言无关的,使得不同语言编写的程序能够互相交换数据。
Lua 中的序列化机制,尤其是简单的实现,通常涉及以下方面的差异:
- Lua代码作为序列化格式:
Lua 的序列化经常直接生成可执行的 Lua 代码(可以是作为一种自描述数据)。
这意味着反序列化通常就是执行这段代码,从而重建原始的数据结构。
这种方式在 Lua 社区中较为常见,因为它利用了 Lua 强大的字符串处理和代码执行能力。 - 没有标准化格式:
Lua 标准库本身并不提供序列化和反序列化功能。
因此,Lua 程序员通常会实现自己的序列化逻辑,或者使用第三方库。
这与像 Python 或 Java 这样内置了序列化机制的语言不同。 - 侧重于可读性和简洁性:
Lua 序列化的一个常见目标是生成可读和简洁的字符串表示,这在配置文件和简单的数据持久化场景中非常有用。 - 安全性问题:
使用 Lua 代码作为序列化格式可能带来安全风险,因为执行反序列化的字符串可能会执行任意代码。
这与 JSON 或 XML 等更为“静态”的格式相比,风险更高。 - 跨语言兼容性不是主要目标:
由于 Lua 序列化通常生成 Lua 代码,这使得生成的数据与其他语言的兼容性不是主要考虑因素。相比之下,JSON 或 XML 格式由于其语言中立性,更适合用于跨语言的数据交换。
总的来说,Lua 的序列化方法倾向于利用其动态语言的特性,生成易于理解和使用的 Lua 代码片段。
这种方法在 Lua 的应用场景中很有效,但可能不适合所有情况,尤其是在需要跨语言兼容性或更高安全性的环境下。在这些情况中,使用 JSON 或其他标准化数据交换格式可能是更好的选择。
对于带循环的表和不带循环的表,序列化和反序列化的步骤及其注意事项略有不同。
10.1.1 不带循环的表
序列化步骤:
- 遍历表:递归地遍历表中的所有键值对。
- 格式化数据:将每个键和值转换为字符串格式。
- 构建字符串:将格式化后的键值对拼接成一个符合 Lua 语法的表表示字符串。
反序列化步骤:
- 解析字符串:使用
load或loadstring函数加载序列化的字符串。 - 执行代码:执行加载的函数来重建原始的表。
示例:
1 | |
注意事项
- 安全性:在反序列化时,确保字符串来自可信的来源。
- 数据类型限制:无法序列化函数、线程、用户数据等。
10.1.2 带循环的表
序列化步骤:
- 追踪循环引用:在序列化过程中追踪已访问的表,以避免无限递归。
- 格式化数据:将每个键和值转换为字符串格式,对于已访问过的表,仅存储引用。
- 构建字符串:构建一个能够在反序列化时重建循环引用的字符串。
反序列化步骤:
- 解析字符串:使用
load或loadstring函数加载序列化的字符串。 - 重建循环引用:执行加载的函数时,确保正确重建循环引用。
示例:
处理循环引用需要更复杂的逻辑。这里提供一个简化的示例:
1 | |
在这个示例中:
serializeWithRefs函数负责序列化表,处理循环引用,并返回一个可以执行的 Lua 代码字符串。serialize函数是一个辅助函数,用于递归地序列化表和其子表。它使用seen表来追踪已访问过的表并避免循环引用。- 在测试代码中,
myTable包含了指向自身的引用,展示了循环引用的情况。 - 使用
load函数可以反序列化生成的字符串,重建原始的表结构,包括其循环引用。
注意事项:
- 循环引用处理:在序列化时需要特别注意循环引用的处理。
- 安全性:反序列化时,确保字符串来自可信的来源。
- 复杂度:带循环引用的表的序列化和反序列化逻辑比不带循环引用的表更复杂,可能需要更多的错误处理和边界情况检
10.2 字节流
当我们需要对序列化后的字符流进行加密传输时,将字符流转成字节流,然后再进行加密操作,是一个不错的选择。
将序列化后的字符串(字符流)转换为字节流,以及将字节流转回字符串,在 Lua 中可以通过一些基本的字符串操作来实现。这里有两个步骤:首先将字符串转换为字节流,然后再将字节流转换回字符串。
有四个相关的函数:
string.byte()
将目标字符转化为字节string.char()
将目标字节转化为字符string.pack
将目标字符流转化为字节流string.unpack
将目标字节流转化为字符流
两种方法对比:
string.pack 和 string.unpack 是 Lua 5.3 引入的两个非常强大的函数,专门用于处理字节流和二进制数据。这些函数提供了一种更高效、更系统化的方式来处理字节流的打包(序列化)和解包(反序列化)。
使用 string.pack 和 string.unpack 而不是手动处理字节流的好处包括:
- 效率更高:这些函数是为高效处理二进制数据而设计的,比手动遍历字符串和构建字节表要高效得多。
- 更广泛的数据类型支持:可以处理各种数据类型,包括整数、浮点数、字符串等,并允许指定不同的字节大小和端序。
- 更简单的语法:只需一行代码就能完成复杂的数据打包和解包操作,而不是多行循环和条件语句。
- 更好的数据控制:可以精确控制数据如何被编码和解码,例如指定整数是 32 位还是 64 位,是大端序还是小端序。
10.2.1 字符流转字节流
string.pack()
功能:
将目标字符流打包成字节流,这个函数特别适用于需要将数据以二进制形式存储或传输的场景。
参数:
- 格式字符串:
定义了如何将参数打包成二进制数据。它由一系列格式字符组成,每个字符指定一个值的类型和大小。 - 值:
根据格式字符串指定的类型和数量,传入的值将被打包成二进制形式。
格式字符串:
基本格式字符:
b:一个有符号的字节(8 位)。B:一个无符号的字节(8 位)。h:一个有符号的短整数(16 位)。H:一个无符号的短整数(16 位)。l:一个有符号的长整数(32 位)。L:一个无符号的长整数(32 位)。j:一个有符号的 lua_Integer。J:一个无符号的 lua_Integer。T:一个无符号的 size_t。f:一个单精度浮点数(32 位)。d:一个双精度浮点数(64 位)。n:一个 lua_Number。i[n]:一个 n 位的有符号整数。例如,i16表示 16 位有符号整数。I[n]:一个 n 位的无符号整数。例如,I16表示 16 位无符号整数。s[n]:
一个长度前缀的字符串,n是长度字段的大小(默认为size_t)。例如,s2表示使用 2 字节长度前缀的字符串。c[n]:
一个固定长度的字符串,由n指定长度。如果字符串短于n,则用零填充;如果长于n,则截断。z:以零结尾的字符串。x:一个填充字节(忽略的字节)。Xop:
对齐选项,op是一个数字,用于指定数据的对齐方式。例如,X4表示 4 字节对齐。
复合格式字符:
A:一个以长度A对齐的块(A是一个数字)。>:后续的数据采用大端序(网络序)。<:后续的数据采用小端序。
注意事项:
- 不同平台和不同 Lua 版本对于整数和浮点数的处理可能有所不同,特别是在大小(32 位 vs 64 位)和字节序(大端 vs 小端)方面。
- 在使用
s[n]、c[n]和z时要注意字符串的长度和结束符,以避免数据截断或错误的填充。 x和Xop对于处理特定格式的二进制数据(如协议字段对齐)很有用,但在一般用途中可能不常见。- 使用大端序或小端序格式字符(
>和<)可以确保在不同架构的系统间正确交换数据。
返回值:
返回一个二进制字符串,其中包含按照格式字符串指定的方式打包的所有值。
使用案例:
1 | |
在这个例子中,i4 表示一个 4 字节的整数,s 表示一个长度前缀的字符串。
函数将 num1、num2 和 str 打包成一个二进制字符串。
注意事项:
- 确保了解每个格式字符的含义,以正确地打包数据。
- 使用与系统架构一致的格式(如字节大小和端序)。
- 避免在安全敏感的应用中使用不受信任的格式字符串,以防止潜在的安全漏洞。
string.byte()
功能:
用于提取字符串中一个或多个字符的数值编码。这在需要分析或操作字符串的单个字符时非常有用。
参数:
- 字符串:需要提取字节的字符串。
- 开始位置(可选):从字符串中提取字节的起始位置,默认为 1(字符串的开始)。
- 结束位置(可选):提取字节的结束位置,默认为开始位置,即默认提取单个字节。
返回值:
返回从指定位置开始的一个或多个字符的整数 ASCII(或 Unicode)值。如果指定了范围,则返回对应范围内每个字符的 ASCII 值。
使用案例:
1 | |
注意事项:
- 字符串索引从 1 开始,不是从 0 开始。
- 确保索引在字符串的有效范围内,否则
string.byte返回nil。 - 对于非标准 ASCII 字符(如 Unicode 字符),返回值可能不是预期的单字节编码。
10.2.2 字节流转字符流
string.unpack
功能:
用于从二进制字符串中解析出按照指定格式打包的数据。
它与 string.pack 相对应,用于读取由 string.pack 生成的二进制数据。
参数:
- 格式字符串:
与string.pack使用的格式字符串相同,定义了如何从二进制数据中解析值。 - 二进制字符串:
包含了要解包的数据。 - 初始位置(可选):
从二进制字符串中开始解包的位置,默认为 1。
返回值:
返回解包后的值,以及下一个未处理字节的位置。
使用案例:
1 | |
在这个例子中,使用与打包时相同的格式字符串来解包 packed 字符串,获取原始的值。
注意事项:
- 确保解包格式与打包时使用的格式一致。
- 在处理大型或复杂的二进制数据时要注意性能和内存使用。
- 解包时要考虑数据对齐和端序,特别是在跨平台应用中。
string.char()
功能:
用于根据提供的一个或多个 ASCII 值构造字符串。这在需要从字符编码生成字符串时非常有用。
参数:
接受一个或多个整数作为参数,每个整数对应一个字符的 ASCII(或 Unicode)值。
返回值:
返回一个字符串,由所有提供的 ASCII 值对应的字符组成。
案例:
1 | |
注意事项:
- ASCII 值应在有效的字符编码范围内(通常是 0 到 255)。
- 对于非单字节编码(如 Unicode),
string.char可能无法正确生成预期字符。 - 当使用超出有效范围的值时,行为可能是未定义的。
练习题
题目描述: 编写一个 Lua 程序,包括以下功能:
- 序列化:
编写一个函数serializeTable,它接受一个可能包含循环引用的表,并将其序列化为一个字符串。确保处理循环引用的情况。 - 反序列化:
编写一个函数deserializeTable,它接受一个序列化的字符串,并将其反序列化为 Lua 表。 - 字节流转换:
- 编写一个函数
convertToByteStream,将给定的字符串使用string.pack转换为字节流。 - 编写一个函数
convertFromString,将给定的字节流使用string.unpack转换回原始字符串。
- 编写一个函数
- 测试:
在测试部分,创建一个包含循环引用的表,序列化它,然后反序列化,并展示转换字节流的过程。
示例代码框架:
1 | |
预期输出:
- 序列化的字符串表示。
- 反序列化的表内容。
- 字节流表示。
- 字节流转换回的原始字符串。
11. 垃圾收集
Lua语言通过垃圾收集(GarbageCollection)自动地删除成为垃圾的对象,从而将程序员从内存管理的绝大部分负担中解放出来,例如无效指针,内存泄露等问题。
Lua的GC的主要机制有3部分
- 弱引用表(weak table)
用于收集Lua中还可以被程序访问的对象 - 析构器(finalizer)
用于收集不在垃圾收集器直接控制下的外部对象 - collectgarbage函数
用于控制垃圾收集器的步长
11.1 垃圾收集器
Lua 中的垃圾收集(Garbage Collection,简称 GC)是一种自动内存管理机制,用于回收程序不再使用的内存。
Lua 的垃圾回收器基于标记-清除算法,并通过一些优化来提高效率。
11.1.1 原理
以下是 Lua 垃圾回收的基本原理:
- 可达性分析:
Lua 的垃圾回收器主要通过可达性分析来判断对象(如表、函数、用户数据等)是否还“活着”。
一个对象如果可以从全局变量或某个活跃的栈上的变量通过一系列引用访问到,那么这个对象就被认为是可达的,即它还“活着”。 - 标记-清除算法:
Lua 垃圾回收的核心是标记-清除算法,该算法分为两个阶段:- 标记阶段:遍历所有可达的对象,并标记它们为活动的。
- 清除阶段:遍历所有对象,回收那些未被标记的对象所占用的内存。
- 增量收集:
为了避免长时间的暂停(Pause),Lua 实现了增量垃圾回收。在增量回收中,垃圾回收过程被分解成一系列小步骤,这些步骤在程序的执行过程中逐渐完成。
Lua 选择使用基于可达性的标记-清除算法主要是因为它提供了更好的处理循环引用的能力,并且对于 Lua 这样的动态语言来说,它能更有效地处理各种复杂的数据结构。虽然这种方式可能会导致垃圾回收时的暂停时间相对较长,但通过增量收集的策略,Lua 成功地将这种影响降到了最低。
以下是 Lua 垃圾回收的过程:
- 开始阶段:
垃圾收集开始时,所有对象都是未标记的。 - 根集合标记:
首先标记根集合,根集合通常包括全局变量和当前活跃的函数参数、局部变量等。 - 传递标记:
从根集合开始,遍历所有可达的对象。对于每个可达的对象,标记它并遍历它引用的所有对象。 - 清除阶段:
完成标记后,清除所有未标记的对象。 - 结束:
垃圾回收结束,程序继续运行直到下一次垃圾回收启动。
注意事项:
- 性能考虑:
虽然 Lua 的垃圾回收器设计得比较高效,但在内存使用密集或性能关键的程序中,不当的垃圾回收设置可能会导致性能问题。 - 可达性与循环引用:
在设计数据结构时,需要注意循环引用的问题,因为它们可能会阻止垃圾回收器回收相关的对象。
Lua 的垃圾回收机制在大多数情况下都能很好地工作,但了解其工作原理可以帮助你更好地管理内存使用,特别是在开发大型或资源敏感的应用程序时。
11.1.2 collectgarbage 函数
collectgarbage 函数在 Lua 中用于控制和监控垃圾回收器的行为。
功能:
- 手动控制垃圾回收:允许手动触发或停止垃圾回收过程。
- 调整垃圾回收器行为:修改垃圾回收器的操作参数。
- 监控内存使用:提供当前使用的内存量信息。
应用场景:
- 性能优化:在性能关键的时刻控制垃圾回收,以避免自动垃圾回收带来的性能波动。
- 内存管理:在内存使用达到特定阈值时手动触发垃圾回收。
- 资源紧张的环境:在资源受限的环境下(如嵌入式设备),更精细地管理内存使用。
- 调试和测试:识别和解决内存泄漏或其他内存相关问题。
参数:
collectgarbage 函数可以接受以下参数,用于指定不同的操作:
**”collect”**:执行一次完整的垃圾回收循环。
collectgarbage("collect")**”stop”**:停止垃圾回收器的自动运行。
collectgarbage("stop")**”restart”**:重新启动垃圾回收器的自动运行。
collectgarbage("restart")**”count”**:返回当前使用的内存量(以千字节为单位)。
1
2
3-- 获取当前使用的内存量(以千字节为单位)
local memoryUsed = collectgarbage("count")
print("Memory used (in KB):", memoryUsed)**”step”**:执行垃圾回收的一个步骤。参数是一个整数,表示要运行的步数。
1
2
3-- 执行一定数量的垃圾收集步骤
local stepCount = 200
collectgarbage("step", stepCount)**”setpause”**:设置垃圾回收的暂停时间。参数是一个百分比值。
collectgarbage("setpause", value)value表示在完成一次垃圾收集后,Lua 分配的内存达到上次收集后内存使用量的多少百分比时,将再次启动垃圾收集器。这个值决定了垃圾收集的“积极程度”。可以简单理解为堆多少垃圾清理一次
**”setstepmul”**:设置垃圾回收的步进倍率。参数是一个整数。
collectgarbage("setstepmul", value)
这里的value是一个整数,表示垃圾收集器在每次 Lua 分配内存时执行的工作量。可以简单理解为清理一次垃圾要清理多少
返回值:
- 对于 “collect”、”stop”、”restart”、”step”、”setpause” 和 “setstepmul” 模式:
无返回值。 - 对于 “count” 模式:
返回当前使用的内存量,单位是千字节。
注意事项:
- 性能考虑:
过度或不当使用collectgarbage可能会对程序性能产生不利影响。特别是在高性能需求的场景中,应谨慎使用。 - 内存管理平衡:
手动管理内存可能会打破 Lua 内建的内存管理机制的平衡,需根据具体场景合理使用。 - 调试用途:
在调试和测试阶段,使用collectgarbage可以帮助识别内存问题,但在生产环境中应避免依赖它来解决内存泄漏等问题。 - 步进调整:
在调整步进倍率(”setstepmul”)和暂停时间(”setpause”)时,应理解它们对垃圾回收行为的影响,以避免产生意外的副作用。
11.2 弱引用表
11.2.1 基础原理
Lua 中的弱引用表是一个非常重要的概念,特别是在处理垃圾回收和内存管理时。
在 Lua 中,表(table)可以被设定为弱引用表。
在弱引用表中,表的键值(key)或值(value)不会阻止所引用的对象被垃圾回收器回收。这是通过设置表的元表中的 __mode 字段来实现的。
弱引用表的功能如下:
- 避免循环引用:
弱引用表是解决循环引用问题的有效工具。
在循环引用中,即使对象不再被程序使用,由于相互引用,它们的引用计数不会降至零,导致无法被正常回收。弱引用表允许这些对象被回收。 - 缓存对象:
弱引用表常用于缓存,允许缓存的对象在不再被其他地方引用时自动释放。
弱引用表的类型:
弱键(weak keys):
设置方法:在表的元表中设置__mode字段为"k"。
特点:- 表的键不会阻止所引用的对象被垃圾回收器回收。
- 一旦键所引用的对象被回收,与之关联的键值对也会从表中删除。
应用场景:
常用于需要关联额外数据到对象上,但不希望这种关联阻止对象被回收的情况。
例如,为对象附加元数据或属性,而不影响其生命周期。弱值(weak values):
设置方法:在表的元表中设置__mode字段为"v"。
特点:- 表的值不会阻止所引用的对象被垃圾回收器回收。
- 一旦值所引用的对象被回收,相应的键值对也会从表中删除。
应用场景:
常用于缓存或临时存储数据,其中数据可以被自动清理而不影响程序的其他部分。
例如,缓存一些可能再次需要的计算结果,但这些结果并不是必需的。同时弱键和弱值:
设置方法:在表的元表中设置__mode字段为"kv"。
特点:- 同时应用弱键和弱值的特性。
- 只要键或值被回收,相应的键值对就会从表中删除。
应用场景:
当需要建立对象之间的关联,但不希望这些关联影响对象的生命周期时使用。
例如,在对象之间建立双向引用或关联,但不希望它们因为相互引用而无法被回收。
注意事项:
- 使用弱引用表时要小心,因为它们中的对象可能随时被回收。
- 弱引用表的行为可能会导致程序难以调试,特别是在涉及内存管理的问题时。
弱引用表在内存管理方面提供了很大的灵活性。
通过控制键和值的弱引用性质,可以创建出各种有用的数据结构,如缓存、关联存储、元数据管理等,同时避免了循环引用或不必要的内存占用问题。
然而,使用弱引用表时也需要小心,因为其中的数据可能随时被垃圾回收器回收,因此应确保程序逻辑考虑到这一点。
11.2.2 使用方法
创建一个弱引用表,其值为弱引用:
1 | |
在这个例子中,由于 weakTable 是一个弱引用表,当删除对 a 的引用并进行垃圾回收后,与 a 相关联的值 b 也被回收,因为没有其他强引用指向它。
11.2.3 实际应用
记忆函数
在 Lua 中,使用弱引用表实现记忆函数(Memoization)是一种优化技术,用于提高具有重复计算的函数的性能。
记忆函数通过缓存以前的计算结果来避免重复的计算。
原理:
- 缓存计算结果:
记忆函数通过创建一个内部缓存(在本例中为cache),用于存储函数参数和对应的计算结果。 - 键值对:
函数的参数被用作键,计算结果被存储为值。 - 弱引用:
使用弱引用表作为缓存,确保缓存中的内容不会阻止垃圾回收器回收它们所引用的对象。
功能:
- 减少重复计算:对于具有重复输入的函数,记忆函数避免了重复计算,通过从缓存中检索结果来提高效率。
- 自动管理缓存:使用弱引用表自动管理缓存,当缓存的数据不再被其他地方引用时,它们可以被垃圾回收。
适用场景:
- 递归函数:例如,斐波那契数列的计算。
- 计算成本高的函数:对于计算成本高且经常被重复调用的函数。
- 函数的输出仅取决于输入:即纯函数(Pure Function)。
注意事项:
- 内存使用:
虽然弱引用表会自动管理内存,但如果函数的输入范围非常大,缓存可能会占用大量内存。 - 并发环境:
在多线程或并发环境中,需要考虑线程安全和同步问题。 - 纯函数:
记忆函数最适合应用于纯函数,即函数的输出完全由输入决定,没有副作用。
示例:使用弱引用表实现的记忆函数
1 | |
通过使用弱引用表实现的记忆函数,可以有效地提高函数的性能,尤其是在处理递归或计算密集型任务时。弱引用表的使用确保了缓存不会过度占用内存,从而平衡了性能和资源使用。
对象属性
使用弱引用表来实现对象属性是一种内存管理技术,它允许在对象不再被使用时自动释放其属性,从而避免内存泄漏。
这在创建临时或缓存对象时特别有用,因为它减少了程序员需要手动管理内存的负担。
原理:
- 弱引用表作为属性容器:
使用弱引用表作为存储对象属性的容器。
对象本身作为弱引用表的键,而与之相关的属性存储为对应的值。 - 自动内存管理:
当对象不再被其他地方引用时,由于弱引用表的特性,这个对象以及它的属性将自动被垃圾回收器回收。
功能:
- 属性存储:为每个对象提供一个用于存储其属性的空间。
- 自动清理:当对象不再被引用时,自动清理与该对象关联的属性,减少内存占用。
适用场景:
- 临时对象:
用于管理临时创建的对象及其属性,例如在游戏开发中的临时实体。 - 缓存系统:
在实现缓存机制时,防止长期持有不再需要的对象。 - 数据绑定:
当对象与外部资源(如UI元素)绑定时,确保在对象释放后自动释放这些资源。
注意事项:
- 生命周期管理:
由于属性的生命周期与对象绑定,确保在对象生命周期内合理使用这些属性。 - 调试难度:
由于属性可能随时被回收,调试相关问题可能会更加复杂。 - 内存泄漏风险:
虽然弱引用表有助于自动内存管理,但仍需注意避免在其他地方意外持有对这些对象的引用,以免造成内存泄漏。
通过使用弱引用表来存储对象属性,可以有效地管理对象的生命周期和相关资源,从而简化内存管理并提高程序的稳定性和性能。
示例:
1 | |
瞬表
在 Lua 中,瞬表(ephemeron table)是一种特殊类型的弱引用表,它解决了一些传统弱引用表无法处理的特殊情况。瞬表主要用于在键和值之间建立弱引用关系,而这种关系的弱引用性取决于键是否还被其他地方引用。以下是瞬表的原理、功能、适用场景和注意事项的说明。
原理:
- 键值间的弱引用关系:
在瞬表中,值的生命周期取决于键的生命周期。
只要键是可访问的,与之关联的值也会被保留。
当键不再被访问时,与其关联的值可以被垃圾回收器回收。 - 垃圾回收的处理:
Lua 的垃圾回收器在处理瞬表时,会特别检查这种键值依赖关系。
如果一个值只被它的键所引用,那么这个键值对可以被回收。
功能:
- 处理特殊的弱引用情况:
瞬表允许创建键到值的弱引用,其中值的生命周期依赖于键。 - 自动内存管理:
在键不再被其他地方引用时,自动回收与键关联的值。
适用场景:
- 缓存机制:
用于实现缓存,其中缓存项(值)依赖于特定的对象(键)。 - 资源管理:
管理与对象关联的资源,例如,当对象被销毁时,自动释放与之关联的资源。 - 数据绑定:
在数据绑定场景中,当数据对象不再存在时,自动清理绑定的UI元素或其他资源。
注意事项:
- 对垃圾回收的依赖:瞬表的行为依赖于垃圾回收的实现和时机。
- 调试难度:由于瞬表中的数据可能随时被回收,调试相关问题可能较为复杂。
- 正确的使用:确保理解瞬表的工作原理和限制,避免不当使用导致的潜在问题。
示例:
1 | |
瞬表是 Lua 中处理复杂内存管理场景的强大工具,但需要对其行为有足够的了解和正确的使用方式,以确保程序的稳定性和性能。
11.3 析构器
在 Lua 中,析构器的概念与在其他一些面向对象编程语言中的析构器略有不同。
由于 Lua 是一种基于原型的脚本语言,它不具备内建的类或对象系统,也没有像 C++ 或 Java 那样的析构方法。
然而,Lua 提供了一种机制,称为“元方法”,其中特别的 __gc 元方法可以用来模拟析构器的行为。
原理:
__gc 元方法:
在 Lua 中,当一个具有 __gc 元方法的表被垃圾回收器准备回收时,__gc 元方法会被调用。这提供了一个执行清理任务的机会,类似于其他语言中的析构器。
仅对用户数据有效:
在 Lua 5.1 版本中,__gc元方法仅对用户数据(userdata)有效。
从 Lua 5.2 版本开始,普通的表也可以拥有__gc元方法。
功能:
- 清理资源:
在对象不再需要时,自动执行清理操作,如关闭文件、释放内存等。 - 自动化管理:
管理对象的生命周期,确保在对象生命周期结束时自动执行所需的清理逻辑。
适用场景:
- 资源管理:
用于管理需要显式释放的资源,如文件句柄、网络连接、动态分配的内存等。 - 复杂对象清理:
清理那些具有复杂状态或需要执行特殊清理逻辑的对象。
注意事项:
- 确保被回收:
Lua 的垃圾回收机制基于可达性分析,确保对象最终变得不可达以触发析构器。 - 避免依赖析构器顺序:
由于垃圾回收的顺序是不确定的,应避免编写依赖于析构器调用顺序的代码。 - 不适用于立即清理:
析构器的调用取决于垃圾回收器的运行,可能不会立即执行。
示例:
1 | |
练习题
题目 1:实现一个记忆函数
编写一个 Lua 函数 memoize(f),它接收一个函数 f 并返回一个新的函数。这个新函数应该缓存 f 的结果,以避免对相同输入重复计算。
1 | |
题目 2:使用弱引用表
创建一个弱引用表 weakTable,其中键为弱引用。
插入几个键值对,然后删除对原始键的引用,强制进行垃圾回收,并验证键值对是否被自动移除。
1 | |
题目 3:调整垃圾收集器行为
编写代码来调整 Lua 垃圾收集器的行为。首先设置垃圾收集器暂停为 150%,然后设置步进倍率为 300%。最后,手动触发一次完整的垃圾收集周期,并输出当前内存使用量。